FireEye のデータ サイエンスおよび情報運用分析チームは、Black Hat USA 2020 ブリーフィングに合わせてこのブログ投稿をリリースしました。このブリーフィングでは、オープン ソースの事前トレーニング済みニューラル ネットワークを活用して、悪意のある目的で合成メディアを生成する方法について詳しく説明しています。プレゼンテーションを要約すると、最初に、テキスト、画像、および音声ドメインでカスタマイズ可能な合成メディアを生成するために機械学習モデルを微調整する方法について、3 つの連続した概念実証を示します。次に、Mandiant Threat Intelligence によって最前線で検出された、合成的に生成されたメディアが情報操作 (IO) のために兵器化された例を示します。最後に、合成的に生成されたコンテンツを検出する際の課題を概説し、合成的に生成されたメディアがますます私たちのように見え、話し、書きます。
|
ハイライト
|
背景: 合成メディア、生成モデル、転移学習
合成メディアは決して新しい開発ではありません。特定のアジェンダのためにメディアを操作する方法は、メディア自体と同じくらい古いものです。 1930 年代、ソ連の秘密警察署長は大粛清中に逮捕され処刑された後、ヨシフ スターリンと並んで歩いているところを撮影された後、公式報道写真からレタッチされました。このようなデジタル グラフィック操作は、Photoshop の登場により顕著になりました。その後、2010 年代後半に「ディープフェイク」という用語が造語されました。フェイス スワッピングやリップ シンクなどのテクニックを含むディープフェイク ビデオは長期的に懸念されますが、このブログ投稿はより基本的なものに焦点を当てていますが、テキスト、静止画像、およびオーディオ ドメインにおけるより信頼性の高い合成メディア生成の進歩について議論します。合成メディアを作成するための機械学習アプローチは、生成モデルによって支えられています。生成モデルは、連邦政府のパブリック コメント Web サイトに大量の提出物を作成したり、音声を複製して重役をだまして 24 万ドルを渡したりするために効果的に悪用されています。
合成メディアを生成できるモデルを作成するために必要な事前トレーニングには、数千ドルの費用がかかり、数週間または数か月の時間がかかり、高価な GPU クラスターへのアクセスが必要になる場合があります。ただし、転移学習を適用すると、関連する時間と労力を大幅に削減できます。転移学習では、大量のデータが利用可能な初期タスク用に事前トレーニングされた大規模な汎用モデルから開始します。次に、モデルが取得した知識を活用して、別の小さなデータセットでさらにトレーニングし、その後の関連するタスクで優れたパフォーマンスを発揮できるようにします。モデルをさらにトレーニングするこのプロセスは微調整と呼ばれ、ゼロからの事前トレーニングに比べて通常は必要なリソースが少なくて済みます。これは、より関連性の高い言葉で考えることができます。あなたがプロのテニス選手であれば、バドミントンを上達させるためにラケットの振り方を完全に再学習する必要はありません.

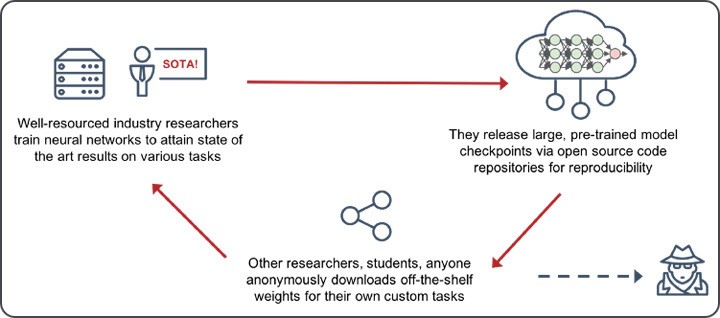
ただし、実際には、転移学習の利点は、人々が事前トレーニング済みのモデルを共有した場合にのみ実現されます。図 1 に示すように、十分なリソースを備えた業界および学術研究者が、最新技術 (SOTA) の研究が一流の会議に受け入れられると、モデル チェックポイントをリリースするのが一般的であることがわかります。コードは通常、広範な HOWTO ガイドと十分に文書化された README を含む GitHub リポジトリの形式でリリースされます。これにより、誰もが最初の論文の図を簡単に再現でき、このソース コードを独自の研究やプロジェクトの出発点として使用できる可能性があります。このプロセスは循環的に実行され、健全で自己強化的なモデル サプライ チェーンを確保し、最終的に科学的イノベーションのペースを速めます。ただし、この新たなモデル共有エコシステムは、非専門家の参入障壁を有利に下げる一方で、悪意のある目的でオープンソース モデルを活用しようとする人々にも有利に働きます。
しかし、この参入障壁はどれだけ低くなったのでしょうか?微調整は、ゼロからモデルをトレーニングする場合と比較して、時間、コスト、データ サイズ、およびコンピューティングの数分の 1 で実行できます。 GPU アクセスを備えたクラウドでホストされたノートブックであろうと、クラウド GPU インスタンスを 1 日だけ予約したものであろうと、これらのモデルの 1 つを微調整するのにわずか数十ドルのオーダーで話しています。スキル上の微調整は必ずしも些細なことではありませんが、「脳の手術」でもありません。著者やその他のオープン ソースの貢献者は、微調整の方法に関する追加のコードやチュートリアルをリリースすることがよくあります。
ここで説明する事前トレーニング済みのモデルはそれぞれ昨年リリースされたばかりなので、次のセクションのデモは現時点のレンズを通して見る必要があります。ただし、オープンソースのリリースは加速しており、信頼できる合成コンテンツを生成するためのハードルは、今後数年間でさらに低下する可能性があります。
シー・ノー・イーヴル
最初の概念実証として、StyleGAN2 を微調整して、ターゲット個人になりすますカスタム ポートレートを生成する方法を示します。 StyleGAN2 は、その前身である StyleGAN と同様に、敵対的生成ニューラル ネットワーク (または GAN) として設計されています。 GAN は、互いに対立する 2 つの基盤となるネットワーク (つまり「敵対的」) で構成されます。データの新しいインスタンスを生成するジェネレーターと、それぞれが実際のトレーニング データセットに属しているかどうかを判断することによってこれらのインスタンスの信頼性を評価するディスクリミネーターです。か否か。事前にトレーニングされた StyleGAN2 の市販品から画像を生成すると、事前にトレーニングされた画像と同様の向きで表示される、ランダムで高品質で多様な画像が出力されます。これらの画像は、StyleGAN2 の元のトレーニング セットには存在しませんが、生成モデルから完全に作成されたものです。これらの人々は実際には存在せず、存在することもありません。
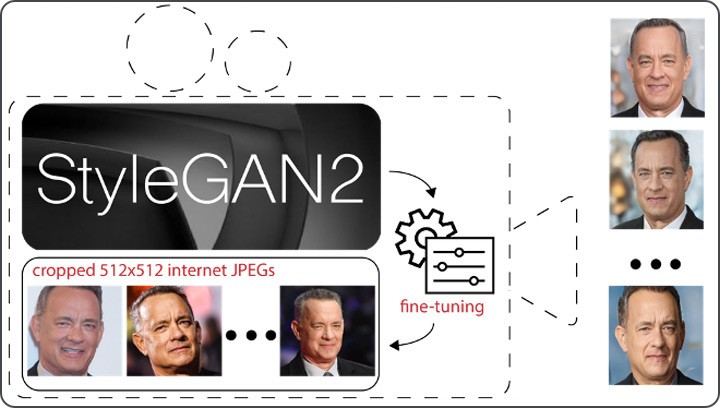
StyleGAN2 は、プライベート データセットで微調整して、オープン ソース モデルのユーザーが制御できるカスタム タスクの出力を生成することもできます。図 2 に示すように、オンラインの画像検索サービスからトム ハンクスの画像を数百枚ダウンロードし、事前トレーニング済みのモデルで必要とされるように、それぞれが顔の中心に配置され、512 x 512 ピクセルになるようにトリミングしました。わずかに小さい学習率を使用して、この新しい小さなデータセットでそれを行います。単一の GPU での微調整に 1 日もかからなかった後、微調整された StyleGAN2 モデルを使用して、ハンクス氏の偽の画像を任意に多数生成しました。これらの画像は、彼の本物のオンライン画像に非常によく似ています。理論的には、選択した任意のターゲットからトリミングされた画像を収集し、同じ演習を実行して、任意の数の偽の画像を生成できます。
悪を聞かない
概念の 2 番目の証明として、音声ドメインに切り替えて、SV2TTS を音声サンプルで微調整して、対象の個人の声になりすます方法を示します。 SV2TTS は複雑な 3 段階のモデルで、ボイス クローニング (任意のテキスト入力からキャプチャされた参照音声へのテキスト読み上げ) をリアルタイムで実行できます。 SV2TTS は、基礎となる 3 つのニューラル ネットワークで構成されています。まず、スピーカー エンコーダーは、人間の音声の抽象的な表現を学習し、それを浮動小数点値の圧縮された埋め込みに絞り込むために、何千ものスピーカーでトレーニングされます。次に、 Google の TacoTron2 に基づくSynthesizer がテキストを入力として受け取り、個々の声の数値表現であるメルスペクトログラムを返します。最後に、 DeepMind の WaveNet に基づくボコーダーがメル スペクトログラムを取得し、それを聞いて理解できる出力波形に変換します。
事前トレーニング済みの SV2TTS を使用して、数百程度の音声の 1 つから任意のテキストを使用して音声を生成できますが、図 3 に示すように、任意のテキストを使用して任意の音声で音声を生成するように微調整することもできます。必要なのは、インターネット経由で自由に録音できるいくつかの音声サンプルを収集し、結果の M4A ファイルのいくつかを事前トレーニング済みの SV2TTS モデルにロードし、それを特徴抽出器として使用して新しい音声波形を合成することだけです。 .例としてハンクス氏を再び使用して、このプロセスの結果を、IO キャンペーンでプッシュされたタイプの物語を主題的に代表する携帯電話の品質解説に似ているように選択したいくつかの入力テキストで示します。 .ここでの特定の例はややロボット的であり、不正確な兆候を示していますが、声の音色は (私たちの主観的な見解では) ハンクス氏の音色に似ています。元の SVT2TTS トレーニング データセットのいずれにも、テキストも音声も存在しません。これを行うために GPU さえ必要としなかったことは注目に値します。事前トレーニング済みのモデルは、基本的なラップトップの CPU コアを使用してローカルで微調整されています。これは、リソースを増やすことで品質の向上が可能であることも示唆しています。
図 3: SV2TTS を微調整することにより、任意のターゲットから携帯電話品質のスピーチ オーディオを生成できます。これには、インターネット上で録音されたオーディオ ファイルまたはビデオ ファイル (左下の 3 つのサンプル クリップなど) を使用します。そのスピーカーは、私たちが制御する任意のカスタム テキストを口述します (たとえば、右側の 3 つのオーディオ サンプル)。
悪を話すません
私たちの最後の概念実証はテキスト ドメインにあります。ここでは、ソーシャル メディア IO キャンペーンでプッシュされた物語を反映したカスタム ソーシャル メディア投稿を生成するために、GPT-2 を微調整する方法を示します。 GPT-2 は、原因言語モデリング タスクでトレーニングされたオープン ソースのニューラル ネットワークであり、その目的は、前のコンテキストから文の次の単語を予測することです。事前トレーニング済みのモデルは最終的に言語生成が可能になります。モデルが次の単語を正確に予測できる場合、次の単語を予測するために使用することができ、最終的にモデルが完全に一貫性のある言語を生成するまで、それを繰り返します。文と段落。
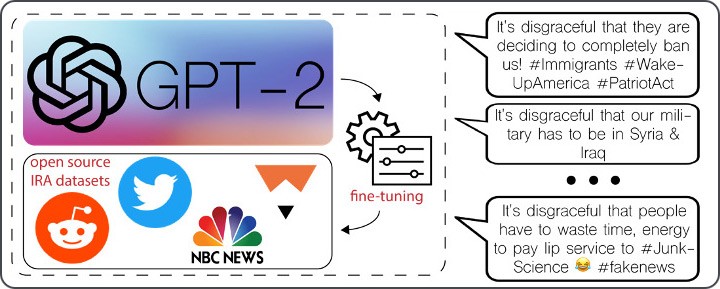
事前トレーニング済みの GPT-2 モデルの出力には、元の平凡なデータセット内に存在するテキストに対応する、比較的形式的な文法、句読点、および構造が表示されます。 GPT-2 の世代を、ソーシャル メディアをスクロールして遭遇する可能性のある投稿のように見せるために、長さが短く、非公式の文法、不規則な句読点、構文上の癖があるため、追加のトレーニング データを使用して新しい言語モデリング タスクで微調整しました。 .このデータは、ロシアの有名なインターネット リサーチ エージェンシーまたは IRA の「トロール ファクトリー」が運営するアカウントからのオープン ソース ソーシャル メディア投稿で構成されていました。 これらのソーシャル メディアの投稿を事前トレーニング済みモデルで処理することにより、単一の GPU で GPT-2 を数時間微調整しました。その後、そのアクティベーションは、調整可能な重みを介して線形出力レイヤーに供給されました。結果として生じる偽の投稿は、短いながらも辛辣で、政治問題に関する怒りを表明し、生成されたテキストの最後に位置的に現れるハッシュタグや絵文字などの特異性を含んでいます。
野生の合成メディア
IO アクターは、合成メディアの増強を容易に助長するさまざまな戦術を使用します。たとえば、私たちが発見し、 「著名ななりすまし」と名付けた影響力のあるキャンペーンには、ジャーナリストのペルソナを偽造し、現実世界の専門家や政治家に手を差し伸べて、イランの政治的課題を推進する音声およびビデオのインタビューを不誠実に求めることが含まれます。別の一般的に使用される戦術は、クロスプラットフォームのオンライン ペルソナの開発です。これは、ターゲット グループに侵入したり、特定の視聴者に捏造されたコンテンツを広めたりするために使用されます。ロシアの安全保障上の利益に沿った捏造されたコンテンツ。また、他の非常に一般的な手法には、実在の個人の写真を流用して偽のペルソナを保護することや、ソーシャル メディアで同一のテキストを繰り返し使用して政治的論評を「人工芝」にすることなどがあります。合成メディアは、そのような戦術の使用と有効性を悪化させる可能性を秘めています。
実際、人為的に生成されたプロフィール写真を使用して、偽の人物像や偽のソーシャル メディア アカウントのネットワークをすでに頻繁に発見しており、この使用は広まっています。たとえば、香港の民主主義抗議行動や COVID-19 パンデミックをめぐる中国寄りの物語を推し進める、本物ではないソーシャル メディア アカウントの大規模なネットワークが、人工的に生成された写真を多用していることを発見しました。アルゼンチンのある地域の政府関係者を支援することを目的としていると思われる最近の作戦で、合成プロフィール写真を使用した偽のアカウントを特定しました。そして、親キューバ政府と反米国の物語を促進するソーシャル メディア主導の影響力作戦では、偽のアカウントの 1 つのネットワークの背後にいるオペレーターは、「thispersondoesnotexist」画像生成ツールによって配置されたテキスト ボックスを完全に切り抜くことさえ気にしませんでした。使用前に、画像がStyleGAN2で生成されたことを述べています。図 5 に示されている IO キャンペーンで積極的に使用されている人工的に生成された画像の例は、観察された一般的な形式を示しています。これには、ぼやけた背景を持つ密接にトリミングされたヘッドショット、耳、首、肩の周りの異常、アクセサリーなどの完全なレンダリングの困難が含まれます。メガネやイヤリング、幻の髪飾りが信憑性のある領域外に生成されています。
しかし、この戦術のエスカレーションを容易に想像できます。たとえば、特定のマイノリティ グループに対応するターゲット グループまたは地域の実在の人物の画像に基づいてトレーニングされた人工的に生成されたプロフィール写真を使用して、説得力のあるペルソナが作成されます。政治的紛争を扇動したり、敵意や暴力を扇動したりする。実際の政治専門家の声で訓練された著名ななりすましに似たキャンペーンで、合成的に生成された音声インタビューを使用すると、説得力を持って実在の人々に直接働きかける必要がなくなり、俳優の負担が軽減されます。連絡先の詳細やアクターとターゲット間の通信方法など、利用可能な調査の手がかりを減らします。また、合成メディアは、さまざまなテキストベースのコンテンツを大規模に広めようとする攻撃者の障壁を大幅に低下させ、書かれたコンテンツの大規模なコーパスを作成するために必要な労力と、同一のテキストのスニペットを繰り返し再利用する必要性を減らします。

回避検出
合成メディアは、望ましい効果を得るために、圧倒的に信頼できる必要はありません。人々は、言語的特徴や起源にあまりこだわらずに、短くて信頼できるエラーだらけのソーシャル メディア テキストをすばやく消費することに慣れています。ユーザーは質の悪いオーディオやビデオのスニペットを消費することに慣れており、大多数のユーザーは、フィードをスクロールして書かれたコンテンツを高速で取り込む際に、ソーシャル メディア アカウントのプロフィール画像をざっと見るだけで済みます。合成世代に関しては、品質基準が非常に高い必要はありません。急速で大量の情報消費が特徴の世界で、音声ユーザーのサブセットでさえ疑問視しないように「十分」である必要があるだけです。
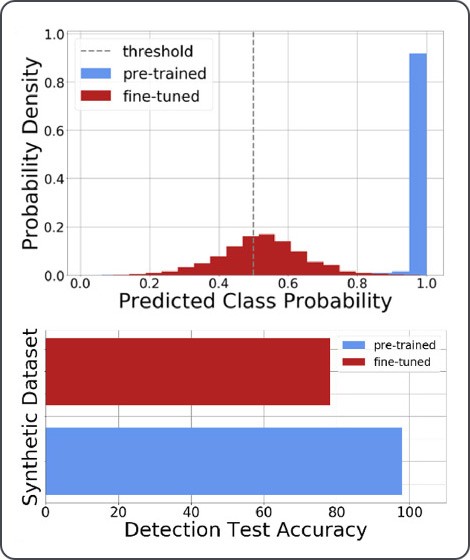
前のセクションで説明したさまざまな潜在的な IO アプリケーションの背後にある共通のテーマは、攻撃者が低コストでキャンペーンを拡大し、検出を回避するのに実質的に役立つということです。特に微調整は、事前に訓練された出力用に構築された分類子と検出モデルを攻撃者がよりうまく回避できるようになるため、ブルーチームにとって問題となります。これは、潜在的な脅威アクターの微調整データセットが非公開であり、テスト時に防御者に知られていない可能性が高いため、懸念されます.この概念は、図 6 で実施したテキストベースの検出実験によって示されています。GPT-2 をリリースした後、 OpenAI は、GPT と同じアーキテクチャまたはトークナイザーを共有しない、RoBERTa に基づいて微調整された分類器とともにソース コードをリリースしました。 2、GPT-2 自身の出力世代と高カルマ Reddit 投稿の元の事前トレーニング データを確実に区別できます。
このRoBERTaモデルを最初に使用して、偽造されたGPT-2生成テキストと本物のGPT-2事前トレーニングデータセットを確実に区別できるという結果を検証しました。分類子を使用して同じ演習を実行し、微調整された IO テキスト生成 (つまり、図 4 で前述したもの) を区別しようとしたところ、精度が大幅に低下しました。事前トレーニング済みのスコア分布が 1 に偏っているという事実は、事前トレーニング済みの世代の検出モデル (分類しきい値が 0.5) が世代を「偽物」として簡単に分類できることを意味します。これにより、図 6 の青で示すように、検出モデルの精度スコアは 97% を超えます。ただし、分類子によって出力されるスコアの分布が偶然に近づくにつれて、微調整された世代の検出精度は約 78% に低下します。 、赤で示されているように。そのため、攻撃者が自分で照合したカスタム データセットを微調整した場合、合成世代を作成するために使用されるデータと、ブルー チームがアクセスできるデータ (または知識さえも) との間に問題のある非対称性が生じる可能性があります。相応の検出モデルを構築します。テキストの長さが短いほど、検出モデルの分類がより困難であることが以前に示されていました。ツイートにヒントを得た実験はこの発見を裏付けていますが、さまざまなデータセット、モデルの複雑さ、入力の長さ、およびハイパーパラメータがこれにどのように寄与するかを解明するには、さらなる研究が必要です。発生器と検出器のいたちごっこの未来に影響を与えます。
結論
合成メディアの生成は、金銭的にも、必要なコンピューティング能力の点でも、より安価になり、より簡単に、より普及し、その出力はますます信頼できるものになり続けています。画像生成機能や商用サービスでさえ、単に顔写真や顔の生成だけでなく、全身ショットや高度なビデオ生成へとすでに移行しており、エンド ユーザーは、世代を特定の属性に向けることができるため、コンテンツ生成の制御と容易さの向上を楽しむことができます。よりきめ細かいレベルで、コンテンツ作成に無料および商用のローコードまたはノーコード アプリケーションの両方を使用できるようになることによって。
このブログ投稿は、現在の情報操作戦術にすぐに適用できることを考えると、研究コミュニティが合成メディアの技術的な検出および軽減機能の開発に引き続き注意を向ける必要があることを強調しています。機械学習分類子やモデルの透かしなどの検出に対する統計的アプローチ、指紋や法医学的指標の署名ベースの識別など、複数の研究手段を追求することができ、また追求する必要があります (図 5 など)。第二に、これらすべてには人間的な側面があります。これには、さまざまな分野の研究者のコミュニティが、検出の課題を克服するためのアプローチ、将来の IO キャンペーンで合成メディアがどのように展開される可能性があるかを脅威モデル化して、潜在的な影響を回避できるようにするためのアプローチを確保することの重要性が含まれます。先制的に対処し、合成メディア生成機能の商用プロバイダーに、脅威アクターによるサービスの潜在的な悪用を認識して説明するよう奨励します。コミュニティの取り組み以外にも、ソーシャル メディアやその他のコンテンツの消費者に、脅威を誤って伝えない責任ある方法で合成メディアのリスクについて意識を高め、教育する必要があります。情報操作と合成メディア。


Comments