序章
機械学習 (ML) は、サイバー セキュリティにおいてますます重要な役割を果たしています。 FireEye では、次のようなさまざまなタスクに ML を採用しています。ウイルス対策、悪意のある PowerShell の検出、 と脅威アクターの行動を関連付ける.多くの人は、モデルが構築された時点でデータ サイエンティストの仕事は終了すると考えていますが、実際には、サイバー脅威は常に変化しており、モデルも変化しなければなりません。初期トレーニングはプロセスの始まりにすぎず、ML モデルのメンテナンスは大量の技術的負債を生み出します。 Google は、論文でこのトピックに関する有益な紹介を提供しています。「機械学習: 技術的負債の高金利クレジット カード。この論文の重要な概念は、エース:何でも変える、すべてを変える. ML モデルは入力データ間の非線形依存関係を意図的に検出するため、データの小さな変更が、モデルの精度と、それらのモデル予測を使用するダウンストリーム システムにカスケード効果を生み出す可能性があります。これにより、サイバー セキュリティ モデリングに内在する矛盾が生じます。(1) 現在の脅威に適応するためにモデルを時間をかけて更新する必要があり、(2) モデルを変更すると予測できない結果が生じる可能性があり、緩和する必要があります。
理想的には、モデルを更新するとき、モデル出力の唯一の変更は、以前のエラーの修正などの改善です。偽陰性 (悪意のある活動を見逃す) と偽陽性 (無害な活動に関する警告) の両方が大きな影響を与えるため、最小限に抑える必要があります。完璧な ML モデルは存在しないため、ホワイトリストとブラックリスト、外部インテリジェンス フィード、ルールベースのシステムなど、直交するアプローチでミスを軽減します。他の情報と組み合わせることで、他の方法では存在しない可能性のあるアラートのコンテキストも提供されます。ただし、 CACE !これらの統合システムは、モデルの更新による意図しない副作用を受ける可能性があります。モデル全体の精度が向上したとしても、モデル出力の個々の変化が改善されるとは限りません。チャーンと呼ばれる、更新されたモデルに新しい偽陰性または偽陽性が導入されると、新しい脆弱性や、モデルの出力を消費するサイバー セキュリティ インフラストラクチャとの否定的な相互作用の可能性が生じます。この記事では、より大規模なサイバー セキュリティ製品を検討する際にチャーンがどのように技術的負債を生み出すか、およびそれを削減する方法について説明します。
予測チャーン
サイバー セキュリティに焦点を当てた ML モデルを再トレーニングするときはいつでも、チャーンを計算して制御できる必要があります。正式には、予測チャーンは、2 つの異なるモデル予測間の予想されるパーセント差として定義されます (予測チャーンは、顧客チャーン (時間の経過に伴う顧客の損失) と同じではないことに注意してください。この用語は、ビジネス分析でより一般的に使用されます)。それはもともとCormierらによって定義されました。さまざまな用途に。サイバー セキュリティ アプリケーションの場合、新しいモデルのパフォーマンスが古いモデルよりも悪いという違いだけに関心があることがよくあります。元のモデルが正しく分類したテスト セット内の誤分類されたサンプルの割合として、分類子を再トレーニングするときの悪いチャーンを定義しましょう。
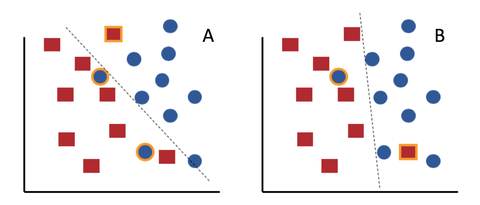
多くの場合、チャーンは驚くべき非直感的な概念です。結局のところ、新しいモデルの精度が古いモデルの精度よりも優れている場合、何が問題なのでしょうか?図 1 の悪意のある赤い四角と無害な青い円の単純な線形分類問題を考えてみましょう。元のモデル A は 3 つの誤分類を行いますが、新しいモデル B は 2 つの誤りしか犯しません。 B はより正確なモデルです。ただし、B は右下隅に新しい誤りを導入し、赤い四角を良性と誤分類することに注意してください。その正方形は、モデル A によって正しく分類されており、悪いチャーンのインスタンスを表しています。明らかに、古いモデルには存在しなかった少数の新しいエラーを導入しながら、全体的なエラー率を下げることが可能です。

図 1: エラーがオレンジ色で強調表示された 2 つの線形分類器。元の分類子 A は B よりも精度が低くなります。ただし、B では右下隅に新しいエラーが発生します。
実際には、チャーンは私たちのモデルに 2 つの問題をもたらします。まず、チャーンが悪いと、ML モデルと組み合わせて使用されるホワイトリスト/ブラックリストの変更が必要になる場合があります。前に説明したように、これらは、少数ではあるが避けられない数の誤った分類を処理するために使用されます。このような変更をキャッチし、関連するホワイトリストとブラックリストを更新するには、大規模なデータ リポジトリでのテストが必要です。第二に、チャーンは、ML モデルの出力に依存する他の ML モデルまたはルールベースのシステムに問題を引き起こす可能性があります。たとえば、ML モデルとノイジー ブラックリストの両方を使用して URL を評価する架空のシステムを考えてみましょう。次の場合、システムはアラートを生成します。
- P(URL = ‘悪意のある’) > 0.9 または
- P(URL = ‘malicious’) > 0.5 かつ URL がブラックリストに載っている
再トレーニング後、P(URL=’malicious’) の分布が変化し、すべての .com ドメインがより高いスコアを受け取ります。アラート ルールは、組み合わせたシステムの必要な全体的な精度を維持するために再調整する必要がある場合があります。最終的に、チャーンを減らす方法を見つけることで、この種の技術的負債を最小限に抑えることができます。
実験のセットアップ
オープン ソースのマルウェア分類データ セットである EMBER を使用して、チャーンとチャーン削減手法を探っていきます。これは、2017 年に最初に確認された 110 万個の PE ファイルと、それらのラベルと機能で構成されています。目的は、ファイルをグッドウェアまたはマルウェアとして分類することです。モデル間のチャーンを計算するために、モデルを 1 つではなく 2 つ構築する必要があります。データセットを 3 つの部分に分割しました。
- 1 月から 8 月までを学習データとして使用
- 9 月と 10 月は、運用環境でのモデルの実行と再トレーニングをシミュレートするために使用されます (図 2 のテスト 1)。
- 11 月と 12 月は、ステップ 1 と 2 のモデルを評価するために使用されます (図 2 のテスト 2)。
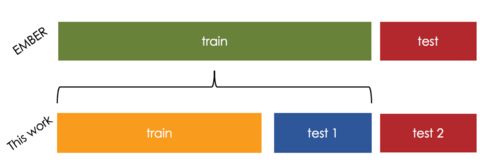
図 2: 実験セットアップと元の EMBER データ分割の比較。 EMBER には 10 か月のトレーニング セットと 2 か月のテスト セットがあります。私たちのセットアップでは、データを 3 つのセットに分割してモデルのトレーニングをシミュレートし、最終的な評価のために独立したデータ セットを保持しながら再トレーニングを行います。
図 2 は、データ分割と、元の EMBER データ分割との比較を示しています。トレーニング データにLightGBM分類器を構築しました。これをベースライン モデルと呼びます。本番テストをシミュレートするために、テスト 1 でベースライン モデルを実行し、FP と FN を記録します。次に、トレーニング データとテスト 1 の FP/FN の両方を使用してモデルを再トレーニングします。このモデルを標準の再トレーニングと呼びます。これは、実際の生産データ収集とモデルの再トレーニングのかなり現実的なシミュレーションです。最後に、ベースライン モデルと標準の再トレーニングの両方がテスト 2 で評価されます。標準の再トレーニングは、テスト 2 のベースラインよりも精度が高く、それぞれ 99.33% 対 99.10% です。ただし、ベースラインまたは 0.12% の悪いチャーンによって行われなかった、再トレーニング モデルによって行われた 246 の誤分類があります。
増分学習
再トレーニングの理論的根拠は、コンセプトのドリフトなど、サイバーセキュリティの脅威が時間の経過とともに変化することであるため、増分学習などの手法を使用して再トレーニングを処理することは自然な提案です。増分学習では、以前に学習した (すべての) 概念を忘れることなく、新しいデータを使用して新しい概念を学習します。これはまた、ベースライン モデルで学習した概念が新しいモデルにまだ存在するため、段階的にトレーニングされたモデルのチャーンはそれほど多くない可能性があることも示唆しています。すべての ML モデルが増分学習をサポートしているわけではありませんが、線形およびロジスティック回帰、ニューラル ネットワーク、および一部の決定木はサポートしています。他の ML モデルを変更して、インクリメンタル ラーニングを実装できます。この実験では、テスト 1 の FP と FN を使用してトレーニング データを補強することで、ベースラインの LightGBM モデルを段階的にトレーニングし、ベースライン モデルの上にさらに 100 本のツリーをトレーニングしました (合計 1,100 本のツリー)。ベースライン モデルとは異なり、正則化 (L2 パラメータ 1.0) を使用します。正則化を使用しないと、新しいポイントへの過適合が発生しました。増分モデルは、テスト 2 で 0.05% (合計 113 サンプル) の悪いチャーンと 99.34% の精度を示します。もう 1 つの興味深いメトリックは、新しいトレーニング データに対するモデルのパフォーマンスです。テスト 1 のベースライン FP と FN のうち、新しいモデルで修正されるのはいくつですか?段階的にトレーニングされたモデルは、以前の誤った分類の 84% を正しく分類します。非常に広い意味で、以前のモデルの間違いを段階的にトレーニングすることで、古いモデルの「バグ」に対する「パッチ」が提供されます。
チャーンを意識した学習
増分アプローチは、元のモデルと新しいモデルの機能が同一である場合にのみ機能します。たとえば、モデルの精度を向上させるために新しい機能が追加された場合、別の方法が必要になります。精度と低いチャーンの両方が必要な場合、最も簡単な解決策は、トレーニング時にこれらの要件の両方を含めることです。これは Cormier らが採用したアプローチであり、チャーンを最小限に抑えるために、トレーニング中にサンプルに異なる重みを与えました。私たちのアプローチにはいくつかの逸脱があります: (1) すべてのチャーンではなく、悪いチャーン (新しい誤分類を含むチャーン) を減らすことに関心があり、(2) 元の方法の極端なメモリ要件を回避したい. Cormier らと同様の方法で、新しいモデルのトレーニング中に、以前に誤分類されたサンプルの重み (重要性など) を減らしたいと考えています。実際には、このモデルは、以前のモデルと同じ過ちを犯すことは、新たな過ちを犯すよりも安価であると考えています。私たちの重み付けスキームは、元のモデルによって正しく分類されたすべてのサンプルに 1 の重みを与え、他のすべてのサンプルには次の重みがあります: w = α – β |0.5 – P old ( χ i )|、ここでP old ( χ i )サンプルχ iおよびα 、 βに対する古いモデルの出力は、調整可能なハイパーパラメータです。 α 0.9、 β 0.6、および増分モデルと同じトレーニング データを使用して、この減少チャーン オペレーター モデル (RCOP) をトレーニングします。 RCOP は、テスト 2 で 0.09% の悪いチャーン、99.38% の精度を生成します。
結果
図 3 は、テスト セット 2 の各モデルの精度と悪いチャーンの両方を示しています。ベースライン モデル、標準モデルの再トレーニング、増分学習モデル、および RCOP モデルを比較します。
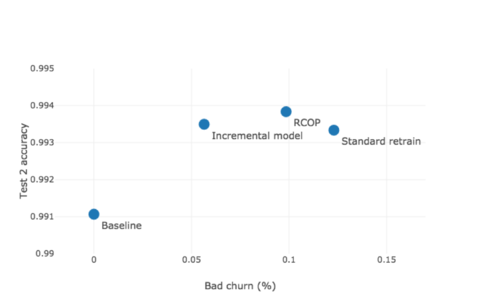
図 3: テスト セット 2 の悪いチャーンと精度。
表 1 は、上記で詳しく説明したこれらのアプローチのそれぞれをまとめたものです。
|
名前 |
訓練を受けた |
方法 |
木の総数 |
|
ベースライン |
訓練 |
ライトGBM |
1000 |
|
標準リトレイン |
テスト 1 のベースラインからトレーニング + FP/FN |
ライトGBM |
1100 |
|
増分モデル |
テスト 1 のベースラインからトレーニング + FP/FN |
ベースライン モデルから始めて、100 個の新しいツリーをトレーニングしました |
1100 |
|
RCOP |
テスト 1 のベースラインからトレーニング + FP/FN |
サンプルの重みを変更した LightGBM |
1100 |
表 1: テストしたモデルの説明
ベースライン モデルでは、他のモデルよりも 100 本少ないツリーがあり、これが比較的低い精度を説明している可能性があります。ただし、ツリーの数を増やしてみましたが、精度は 0.001% 未満の小さな増加にとどまりました。ベースライン以外の方法の精度の向上は、データ セットとトレーニング方法の違いによるものです。増分トレーニングと RCOP の両方が期待どおりに機能し、標準の再トレーニングよりもチャーンが少なく、ベースラインよりも精度が向上しています。一般に、悪いチャーンの増加と相関して精度が向上する傾向が通常あります。フリーランチはありません。決定境界の変化により精度が向上するということは、より多くの改善が行われるほど、より多くの変更が発生するということです。意思決定境界の変化の増加が悪いチャーンの増加と相関していることは合理的に思えますが、常にそうでなければならない理由についての理論的な正当化は見られません.
予想外に、増分モデルと RCOP の両方が、標準の再トレーニングよりも少ないチャーンでより正確なモデルを生成します。追加の制約を考えると、両方のモデルの精度が低くなり、チャーンが少なくなると想定していたでしょう。最も直接的な比較は、RCOP と標準の再トレーニングです。両方のモデルは同一のデータ セットとモデル パラメーターを使用し、各サンプルに関連付けられた重みだけが異なります。 RCOP は、ベースライン モデルによって誤って分類されたサンプルの重みを減らします。その減少は、精度の向上に責任があります。この動作の原因として考えられるのは、トレーニング データのラベルが間違っていることです。複数の著者が、ラベル ノイズのあるポイントを特定して削除することを提案しており、多くの場合、以前にトレーニングされたモデルの誤分類を使用して、これらのノイズのあるポイントを特定しています。これらのポイントを削除する代わりに重みを減らす私たちのスキームは、精度の向上を説明できる他のノイズ削減アプローチと似ています。
結論
ML モデルには固有の問題があります。再トレーニングを行わないということは、新しいクラスの脅威に対して脆弱になることを意味し、再トレーニングを行うとチャーンが発生し、古い脆弱性が再導入される可能性があります。このブログ投稿では、チャーンを減らすために ML モデル トレーニングを変更する 2 つの異なるアプローチについて説明しました。インクリメンタル モデル トレーニングとチャーン認識学習です。どちらも、EMBER マルウェア分類データ セットで有効性を示しており、悪いチャーンを減らし、同時に精度を向上させています。最後に、ラベル ノイズを含むデータ セットのチャーンを減らすと、より正確なモデルが得られるという新しい結論も示しました。全体として、これらのアプローチは、データ サイエンティストや機械学習エンジニアが最小限のコストで最新のサイバー脅威に対してモデルを最新の状態に保つことを可能にする、モデルを更新するための技術的負債の少ないソリューションを提供します。 FireEye では、データ サイエンティストが FireEye Labs の検出アナリストと緊密に連携して、誤分類を迅速に特定し、これらの手法を使用して顧客へのチャーンの影響を軽減しています。


Comments