
Mandiant のマルウェア分析チーム (現在は正式に M-Labs として知られています) に所属して 5 年間、シェルコードのチャンクをリバース エンジニアリングしなければならないことがありました。この投稿では、シェルコードのインポート解決手法の背景と、IDA マークアップを自動化してシェルコードのリバース エンジニアリングを高速化する方法について説明します。
シェルコードの反転
シェルコードの一部が何をするかを判断する最も簡単な方法は、監視対象の環境内で実行できるようにすることです。エクスプロイトによってシェルコードが起動され、脆弱なプログラムの正しいバージョンがない場合、これは機能しない可能性があります。シェルコードを扱った経験では、他のプロセスに挿入されて実行される埋め込みシェルコード バッファを含む多くのマルウェア サンプルを見てきました。ただし、この埋め込まれたシェルコードを正しく実行できるとは限りません。このような状況では、シェルコードの機能を判断するために、シェルコードの静的分析が必要になる場合があります。
通常、シェルコード バイナリはそれほど大きくないため、リバース エンジニアリングが困難になることはありませんが、シェルコードの作成者が使用する一般的な手法には、リバース エンジニアリングを妨げる副作用がしばしばあります。そのような手法の 1 つは、インポート関数を手動で解決するときに API 関数のハッシュを使用することです。
シェルコードのインポートの解決
通常のプログラムを作成する開発者は、 kernel32.dll's LoadLibraryAとGetProcAddressを使用して、任意の DLL をロードし、エクスポートされた関数ポインターを取得できます。通常、シェルコードの作成者はサイズの制約に直面するため、使用したい各 API 関数の完全な文字列を含めることは非常に困難になる可能性があります。完全な文字列を使用するよりも、サイズ効率の良い方法は、関数名の数値ハッシュを事前に計算し、これらの値をシェルコードに含めることです。これにより、シェルコードがGetProcAddressに依存して関数ポインターを取得できなくなるため、インポート解決プロセスが変更されます。代わりに、メモリ内の DLL PE ファイルを解析してエクスポート ディレクトリを見つけ、エクスポート関数の配列をトラバースする必要があります。エクスポート関数名ごとに、シェルコードはハッシュを計算し、それをシェルコードに埋め込まれた値と比較します。値が一致すると、正しい API 関数が見つかりました。この手法の背景情報は、Last Stage of Delirium がwinasmプロジェクト (http://lsd-pl.net/projects/winasm.zip) の一部として発表した論文に記載されています。
これは難しそうに聞こえるかもしれませんが、幸運なことに、ほとんどのシェルコード作成者は既知のハッシュ アルゴリズムと値を再利用しているため、リバース エンジニアの作業が大幅に改善されています。復元されたシェルコード サンプルで見た最も一般的なハッシュ関数は、Metasploit に含まれています。このアルゴリズムは、図 1 の疑似コードで示されています。

ハッシュは決して強力な暗号化ハッシュではありませんが、任意の長さの入力文字列に基づいて整数値を計算するという目標を達成します。ハッシュ アルゴリズムの唯一の実際の制約は、開発者が DLL 内で使用するすべての API 関数が一意のハッシュ値を持つ必要があることです。この単純な ROR-13 計算は非常に効果的です。私が遭遇した異常なハッシュは通常、このアイデアのわずかな変形です: 異なる量だけ回転したり、右ではなく左に回転したり、他の演算子を使用して入力文字列内のすべての文字を混合して整数の結果を形成したりします。 .
シェルコード インポート マークアップの自動化
最初にシェルコードのリバース エンジニアリングを開始するときは、ほとんどの場合、これらの魔法の値をオンラインで検索するか、これらの値を自分で計算して、後で参照できるようにテキスト ファイルに保存します。時間が経つにつれて、より多くのサンプルを確認するにつれて、これは面倒で反復的なタスクであり、IDA スクリプトによる自動化の機が熟していることに気付きました。
シェルコード作成者の間で頻繁にコードが再利用されているため、一連の IDA スクリプトをリリースすることは、マルウェア アナリストにとって役立つと感じました。既知のハッシュ アルゴリズムを使用して一般的な API 関数名を事前に計算することは可能であり、新しいハッシュ アルゴリズムに遭遇した場合、そのハッシュを生成するために実装することはそれほど難しくありません。 Poison Ivy RAT からの文字列ハッシュを含む 1 つのインスタンスしかありませんでしたが、そうではありませんでした。
スクリプトは、Mandiant GitHub リポジトリ ( https://github.com/mandiant/Reversing ) で見つけることができます。
次の 2 つの部分があります。
make_sc_hash_db.pyは、関数名ハッシュの事前計算を担当します。これは、私が過去に遭遇したハッシュ アルゴリズムの実装を含むコマンドライン Python スクリプトです。 DLL のディレクトリを処理し、各エクスポート関数のハッシュを計算し、これらすべてを SQLite データベースに格納します。-
shellcode_hash_search.py is an IDAPython script that opens the SQLite database containing the precalculated hashes and searches th。
make_sc_hash_db.pyは、図 2 に示すように実行できます。最初の引数は作成する SQLite データベースの名前で、2 番目の引数は関連する DLL を含むディレクトリです。この手順を省略したい場合は、配布物にサンプル データベースが含まれています。
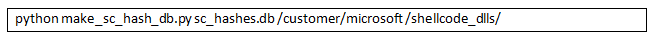
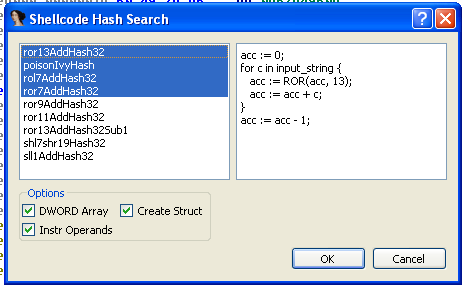
shellcode_hash_search.py IDAPython スクリプトが実行されると、使用するデータベースをユーザーに要求し、追加の検索パラメーターをユーザーに照会します。データベースに格納されているすべてのハッシュ アルゴリズムが表示され、図 3 に示すようにいくつかの単純な疑似コードが提供されます。このスクリプトは、HexRays が配布する QT 用の PySide Python バインディングを使用しようとします (IDA の別のダウンロードとしてhttp://www. hex-rays.com/products/ida/support/download.shtml )。 PySide の HexRays ディストリビューションが含まれていない場合、ユーザーから同じ情報を取得するために一連の単純なダイアログを表示するようにフォールバックします。
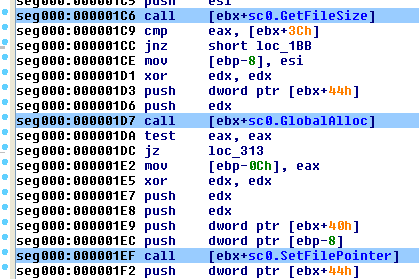
何も強調表示されていない場合、スクリプトは強調表示された領域または現在のセグメントを検索します。検索プロセスは、各 DWORD ( DWORD Arrayオプションがオンの場合) および各命令オペランド ( Instr Operandsオプションがオンの場合) を照会して、選択したハッシュ アルゴリズムの既知のハッシュであるかどうかを判断します。ハッシュ値が見つかると、IDA に行コメントが追加されます (図 4 参照)。
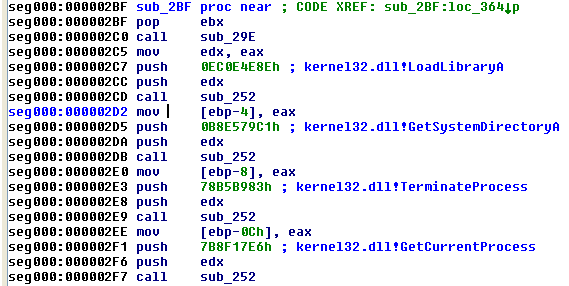
また、シェルコードの作成者は、関数の引数として各ハッシュをプッシュするのではなく、ハッシュの DWORD 配列を使用することも一般的です。これを図 5 に示します。
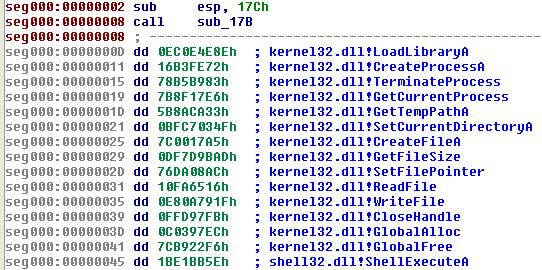
[ Create Struct ] オプションがオンになっていて、ハッシュ値が連続したアドレスで見つかった場合、スクリプトは図 6 に示すように IDA 構造を作成します。
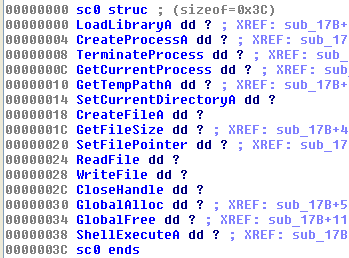
この構造体は、アナリストが[base+index]参照を構造体参照に変換できるようにするため、シェルコード作成者がこれを関数ポインターの配列として扱う場合に役立ちます。これを図 7 に示します。この図では、既知の構造オフセットを使用することで呼び出し命令が理解しやすくなっています。
shellcode_hashes_search_plugin.py IDAPython プラグインは、IDA のプラグイン メニューからこの機能を利用したい場合に提供されます。このファイルを%PROGRAMFILES%IDApluginsディレクトリにコピーし、 PYTHONPATH環境変数を正しく設定して、他の Python ファイルにアクセスできるようにします。
結論
多くの場合、シェルコードのリバースは、通常のバイナリのリバースよりもはるかに面倒です。 IDA によって解決された輸入の欠如は、反転タイムラインが遅くなった大きな理由です。上記で説明し、GitHub ページでリリースした IDAPython スクリプトを使用することで、シェルコードの反転が改善されることを願っています。
参照: https://www.mandiant.com/resources/blog/precalculated-string-hashes-reverse-engineering-shellcode


Comments