ユーザーをマルウェアから保護するために、機械学習 (ML) 技術に依存する最新のウイルス対策ソリューションの数が増えています。 FireEye Endpoint Security の MalwareGuard 機能のような ML ベースのアプローチは、新しい脅威の検出に優れた成果を上げていますが、相当な開発コストも伴います。有用な機能の大規模なセットを作成してキュレートするには、マルウェア アナリストやデータ サイエンティストの膨大な時間と専門知識が必要です (このコンテキストでは、機能とは、グッドウェアとマルウェアを区別するために使用できる実行可能ファイルのプロパティまたは特性を指すことに注意してください)。 .しかし近年、深層学習のアプローチは、画像、音声、テキストなどの複雑な問題領域の特徴表現を自動的に学習することにおいて、印象的な結果を示しています。ディープ ラーニングのこれらの進歩を利用して、コストのかかる機能エンジニアリングを行わずにマルウェアを検出する方法を自動的に学習できるでしょうか?
結局のところ、ディープ ラーニング アーキテクチャ、特に畳み込みニューラル ネットワーク (CNN )は、 Windows Portable Executable (PE) ファイルの raw バイトを調べるだけで、マルウェアを適切に検出できます。過去 2 年間、FireEye はマルウェア分類のためのディープ ラーニング アーキテクチャとそれらを回避する方法を実験してきました。私たちの実験では、手動の機能エンジニアリングのコストを回避しながら、従来の ML ベースのソリューションと競合する驚くべきレベルの精度が実証されました。私たちの調査結果が最初に発表されて以来、他の研究者も同様に印象的な結果を発表しており、精度は 96% を超えています。
これらの深層学習モデルは、追加の構造的、意味的、または構文的なコンテキストなしで生のバイトのみを調べているため、マルウェアとグッドウェアを区別するものをどのように学習できるのでしょうか?このブログ投稿では、FireEye のディープ ラーニング ベースのマルウェア分類器を分析することで、この質問に答えます。
|
ハイライト
|
バックグラウンド
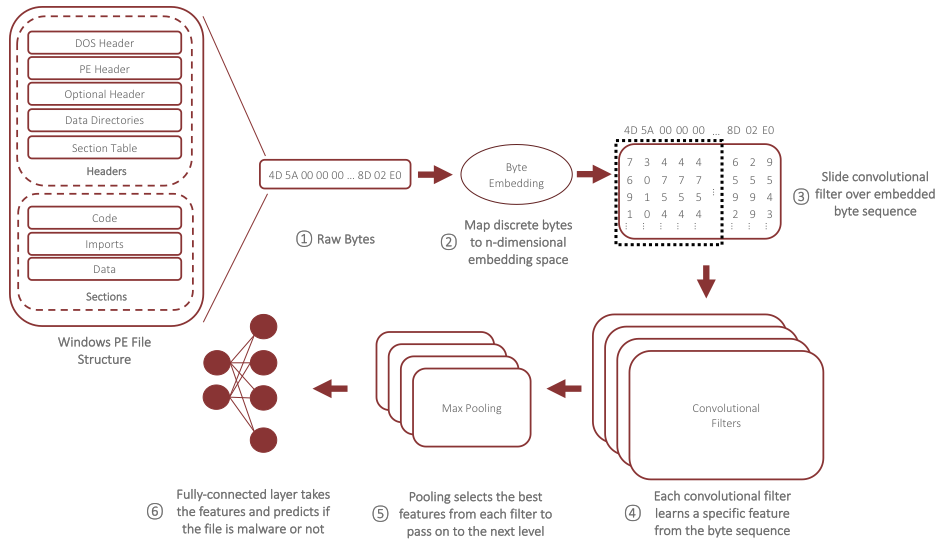
分析に入る前に、まず CNN 分類器が Windows PE ファイル バイトに対して何を行っているかについて説明しましょう。図 1 は、生の実行可能データから「学習」している間に分類子によって実行される高レベルの操作を示しています。存在する可能性のある構造が存在しない、実行可能ファイルの生のバイト表現から始めます (1)。この生のバイト シーケンスは埋め込み各バイトが値の n 次元ベクトルに置き換えられる高次元空間に変換します (2)。この埋め込みステップにより、CNN は離散バイト間の関係を n 次元内で移動することによって学習できます。埋め込みスペース.たとえば、バイト 0xe0 と 0xe2 が同じ意味で使用されている場合、CNN はこれらの 2 つのバイトを埋め込み空間内で近づけることができるため、一方を他方に置き換えるコストが小さくなります。次に、実行します畳み込み埋め込まれたバイト シーケンスに対して (3)。トレーニングセット全体でこれを行うと、畳み込みフィルターグッドウェアとマルウェアを区別する特定のシーケンスの特徴を学習し始めます (4)。簡単に言えば、埋め込まれたバイト シーケンス全体で固定長のウィンドウをスライドさせ、畳み込みフィルターがそれらのウィンドウ全体から重要な機能を学習します。シーケンス全体をスキャンしたら、次のことができますプール次のレベル (5) に渡すために、シーケンスの各セクション (つまり、フィルターを最大限にアクティブ化したもの) から最良の機能を選択するための畳み込み活性化。実際には、畳み込み操作とプーリング操作は、階層的な方法で繰り返し使用され、多くの低レベルの特徴を分類に役立つ少数の高レベルの特徴に集約します。最後に、プーリングから集約された特徴を入力として使用します完全に接続されたニューラル ネットワーク、これは PE ファイルのサンプルをグッドウェアまたはマルウェアのいずれかに分類します (6)。

ここで分析する特定の深層学習アーキテクチャには、実際には 5 つの畳み込み層と最大プーリング層が階層的に配置されており、階層の下位レベルで発見されたものを組み合わせることで複雑な機能を学習できます。このようなディープ ニューラル ネットワークを効率的にトレーニングするには、入力シーケンスを固定長に制限する必要があります。この長さを超えるバイトは切り捨てるか、特殊なパディング シンボルを使用して小さなファイルに入力します。この分析では、1MB を超える長さで実験しましたが、100KB の入力長を選択しました。 1,500 万を超える Windows PE ファイルで CNN モデルをトレーニングしましたが、その 80% は正規のソフトウェアで、残りはマルウェアでした。 2018 年 6 月から 8 月にかけて実環境で観察された約 900 万個の PE ファイルのテスト セットに対して評価した場合、分類器は 95.1% の精度と 0.96 のF1 スコアを達成しました。これは、以前の研究で報告されたスコアの上限です。
この分類子がマルウェアについて何を学習したかを理解するために、アーキテクチャの各コンポーネントを順番に調べます。各ステップで、トレーニング データから取得した 4,000 個の PE ファイルのサンプルを使用して幅広い傾向を調べるか、NotPetya、 WannaCry 、および BadRabbit ランサムウェア ファミリからの 6 つのアーティファクトの小さなセットを使用して特定の機能を調べます。
(埋め込み) スペースのバイト数
埋め込みスペースは、分類子が個々のバイトについて学習した興味深い関係をエンコードし、分類子の決定に対する暗黙の重要性のために、特定のバイトが他のバイトとは異なる方法で処理されるかどうかを判断できます。これらの関係を明らかにするために、(1)多次元スケーリング (MDS)と呼ばれる次元削減手法と (2) HDBSCANと呼ばれる密度ベースのクラスタリング手法の 2 つのツールを使用します。次元削減手法により、ポイントの全体的な構造と構成を維持しながら、高次元の埋め込み空間から簡単に視覚化できる 2 次元空間の近似値に移行できます。一方、クラスタリング手法を使用すると、ポイントの密なグループや、近くにポイントがない外れ値を特定できます。根底にある直観は、外れ値はモデルによって「特別」として扱われるということです。これは、アップストリームの計算を大幅に変更せずに簡単に置き換えることができるポイントが他にないためです。一方、ポイントの密集したクラスターは交換可能に使用できます。
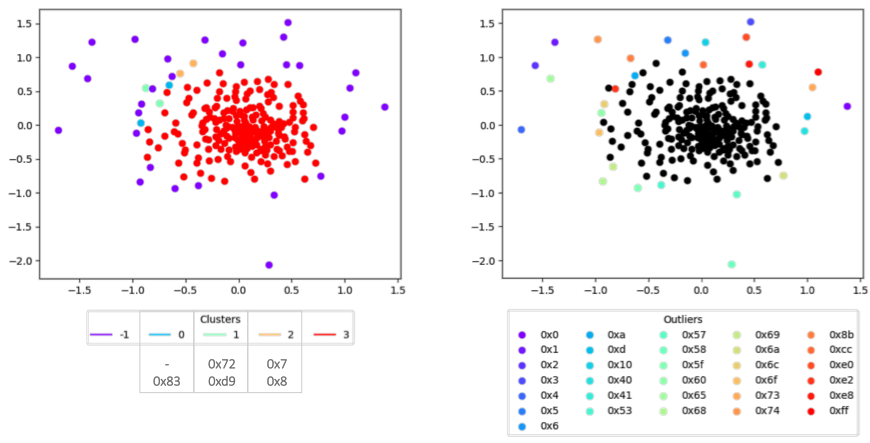
図 2 の左側に、バイト埋め込みスペースの 2 次元表現を示します。各クラスターにはラベルが付けられ、外れ値クラスターには -1 のラベルが付けられています。ご覧のとおり、バイトの大部分は 1 つの大きな包括的なクラス (クラスター 3) に分類されますが、残りの 3 つのクラスターにはそれぞれ 2 バイトしかありません。これらのクラスタには明確な意味上の関係はありませんが、含まれているバイトはそれ自体興味深いものです。たとえば、クラスタ 0 には、ファイルが固定長のカットオフよりも小さい場合にのみ使用される特別なパディング バイトが含まれています。 1 には ASCII 文字「r」が含まれます。
しかし、もっと興味深いのは、図 3 の右側に示されているように、クラスタリングによって生成された外れ値のセットです。ここには、いくつかの興味深い傾向が現れ始めています。 1 つは、0x0 から 0x6 の範囲の各バイトが存在し、これらのバイトは、短い順方向ジャンプで、またはレジスタが命令引数 (eax、ebx など) として使用される場合によく使用されます。興味深いことに、0x7 と 0x8 はクラスター 2 にグループ化されています。これは、0x7 がレジスタ引数として解釈される可能性がある場合でも、トレーニング データでこれらが同じ意味で使用されていることを示している可能性があります。もう 1 つの明確な傾向は、異常値のセットに「n」、「A」、「e」、「s」、「t」などの ASCII 文字がいくつか存在することです。最後に、call 命令 (0xe8)、loop と loopne (0xe0、0xe2)、ブレークポイント命令 (0xcc) など、いくつかのオペコードが存在することがわかります。
これらの調査結果を考えると、分類子が低レベルの機能で何を探しているのかがすぐにわかります。ASCII テキストと特定のタイプの命令の使用です。
低レベル機能の解読
分析の次のステップは、畳み込みフィルターの最初のレイヤーによって学習された低レベルの機能を調べることです。私たちのアーキテクチャでは、このレイヤーで 96 個の畳み込みフィルターを使用しました。各フィルターは、後続のレイヤーで結合される基本的な構成要素の機能を学習して、有用な高レベルの機能を導き出します。これらのフィルターの 1 つが現在の畳み込みで学習したバイト パターンを検出すると、大きなアクティベーション値が生成され、その値を各フィルターの最も興味深いバイトを識別する方法として使用できます。もちろん、生のバイト シーケンスを調べているので、これはどのファイル オフセットを見るべきかを示すだけであり、データの生のバイトの解釈と人間が理解できるものとの間のギャップを埋める必要があります。そのために、 PEFileを使用してファイルを解析し、 BinaryNinja の逆アセンブラーを実行可能セクションに適用して、各フィルターの学習された機能間で共通のパターンを簡単に識別できるようにします。
調査するフィルターが多数あるため、4,000 個の Windows PE ファイルのサンプル全体でどのフィルターが最も強力なアクティベーションを行っているか、それらのファイルのどこでそれらのアクティベーションが発生しているかを大まかに把握することで、検索を絞り込むことができます。図 3 では、4,000 サンプル データセット全体で最も強い 100 の活性化の場所を示しています。これは、いくつかの興味深い傾向を示しています。そのうちのいくつかは予想できたものであり、他のものはおそらくもっと驚くべきものです. 1 つには、アーキテクチャのこのレベルでのアクティブ化の大部分は、通常、実行可能コードを含む「.text」セクションで発生します。マルウェアとグッドウェアのサブセット間で「.text」セクションのアクティベーションを比較すると、マルウェア セットのアクティベーションの方がはるかに多く、この低レベルであっても、主にマルウェアに見られる特定のバイト シーケンスをキー入力した特定のフィルターがあるように見えます。マルウェア。さらに、「UNKNOWN」セクション (基本的には、PE ファイルの有効な範囲外で発生するすべてのアクティベーション) では、マルウェア グループでより多くのアクティベーションが行われていることがわかります。多くの難読化および回避手法は、データを非標準の場所に配置することに依存しているため (たとえば、PE ファイルを相互に埋め込むなど)、これは直感的に理解できます。
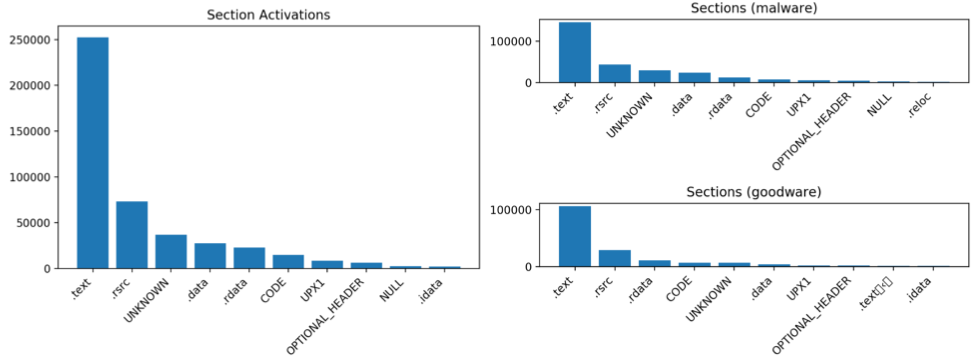
また、図 4 に示すように、4,000 の PE ファイル全体で各フィルターの上位 100 のアクティベーションをプロットすることにより、畳み込みフィルター間のアクティベーションの傾向を調べることもできます。マルウェアのサンプルに含まれています。この場合、フィルター 57 のアクティベーションはマルウェア セットでほぼ排他的に発生するため、後で分析する重要なフィルターとなります。フィルター アクティベーションの分布から得られるもう 1 つの主なポイントは、分布がかなり偏っていることです。このアーキテクチャでは、このレベルでアクティベーションの大部分を処理するフィルターは 2 つしかありません。実際、分析している 4,000 個のファイルのセットでは、一部のフィルターがまったくアクティブ化されていません。
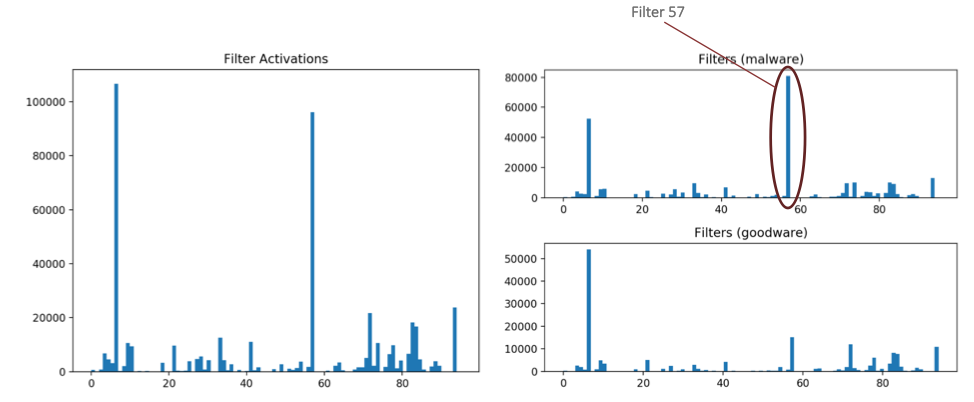
最も興味深くアクティブなフィルターを特定したので、それらのアクティブ化場所の周囲の領域を分解し、いくつかの傾向を引き出すことができるかどうかを確認できます。特に、フィルター 83 と 57 を見ていきます。どちらもアクティベーション値に基づくモデルで重要なフィルターでした。いくつかのランサムウェア アーティファクトに対するこれらのフィルターの分解結果を図 5 に示します。
フィルター 83 の場合、バイトの ASCII エンコーディングを見ると、アクティブ化の傾向がかなり明確になります。これは、フィルターが特定の種類のインポートを検出することを学習したことを示しています。活性化 (「*」で示される) を詳しく見ると、これらには常に「r」、「s」、「t」、「e」などの文字が含まれているように見えますが、これらはすべて外れ値として識別されたか、埋め込み分析中の独自のクラスター。フィルター 57 のアクティベーションの分解を見ると、別の明確なパターンが見られます。ここでは、複数のプッシュ命令と呼び出し命令を含むシーケンスでフィルターがアクティブになり、基本的に、複数のパラメーターを持つ関数呼び出しを識別します。
ある意味では、フィルター 83 と 57 は、同じ包括的な動作の 2 つの側面を検出していると見なすことができます。フィルター 83 はインポートを検出し、フィルター 57 はそれらのインポートの潜在的な使用を検出します (つまり、パラメーターの数と使用法をフィンガープリントすることによって)。畳み込みフィルターの独立した性質により、インポートとその使用法 (たとえば、どのインポートがどこで使用されたか) の間の関係が失われ、分類子はこれらを 2 つの完全に独立した機能として扱います。
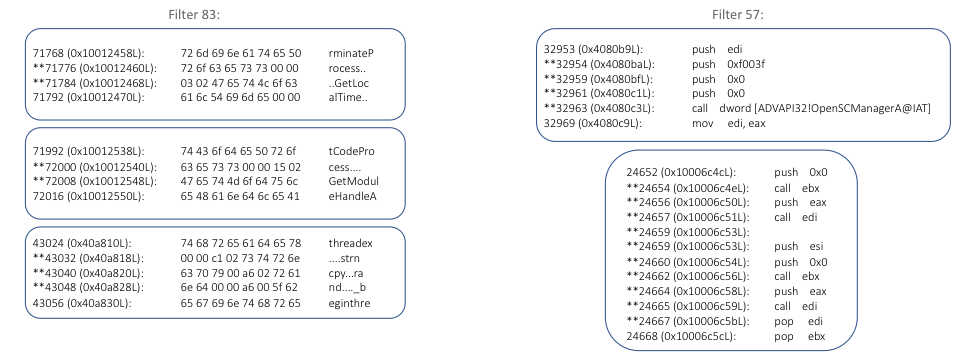
上記のインポート関連の機能とは別に、当社の分析では、DoublePulsar や EternalBlue などのエクスプロイト コードを含む機能で見つかった特定のバイト シーケンスをキー入力するいくつかのフィルターも特定しました。たとえば、フィルタ 94 は、分析した BadRabbit アーティファクトの EternalRomance エクスプロイト コードの一部でアクティブ化されました。これらの低レベル フィルタは、必ずしも特定のエクスプロイト アクティビティを検出するわけではなく、同じ関数内の周囲のコード内のバイト シーケンスでアクティブになることに注意してください。
これらの結果は、エクスプロイト コード内で見つかったインポート、関数呼び出し、アーティファクトに関連する ASCII テキストと命令の使用に関連する特定のバイト シーケンスを分類子が学習したことを示しています。画像などの他の機械学習ドメインでは、低レベルのフィルターがすべてのクラスで一般的で再利用可能な機能を学習することが多いため、この発見は驚くべきものです。
エンドツーエンド機能の鳥瞰図
CNN 分類子の下位層が特定のバイト シーケンスを学習したように見えますが、より大きな問題は次のとおりです。分類子の深さと複雑さ (つまり、層の数) は、階層を上に移動するにつれて、より意味のある特徴を抽出するのに役立ちますか?この質問に答えるには、分類子の決定と各入力バイトの間のエンドツーエンドの関係を調べる必要があります。これにより、入力シーケンス内の各バイト (またはそのセグメント) を直接評価し、それが分類器をマルウェアまたはグッドウェアの決定に押し上げたかどうか、およびその程度を確認できます。この種のエンド ツー エンドの分析を実現するために、Lundberg と Lee によって開発されたSHapley Additive exPlanations (SHAP)フレームワークを活用します。具体的には、多数の手法を組み合わせて各入力バイトの寄与を正確に特定するGradientSHAPメソッドを使用します。正の SHAP 値は悪意のある機能と見なすことができる領域を示し、負の値は無害な機能を示します。
GradientSHAP メソッドをランサムウェア データセットに適用した後、最も重要なエンド ツー エンド機能の多くが、分類子の下位層で発見した特定のバイト シーケンスのタイプに直接関連していないことに気付きました。代わりに、私たちが発見したエンドツーエンドの機能の多くは、従来の ML モデルで手動の機能エンジニアリングから開発された機能に密接にマッピングされていました。一例として、当社のランサムウェア サンプルのエンド ツー エンド分析では、PE ヘッダーのチェックサム部分にいくつかの悪意のある機能が特定されました。これは、従来の ML モデルの機能として一般的に使用されています。その他の注目すべきエンド ツー エンド機能には、PE ファイルの署名に使用される証明書に関連する特定のディレクトリ情報の有無、PE ファイルのさまざまなセクションのプロパティを定義するセクション テーブルの異常、および特定のインポートが含まれます。多くの場合、マルウェア (GetProcAddress や VirtualAlloc など) によって使用されます。
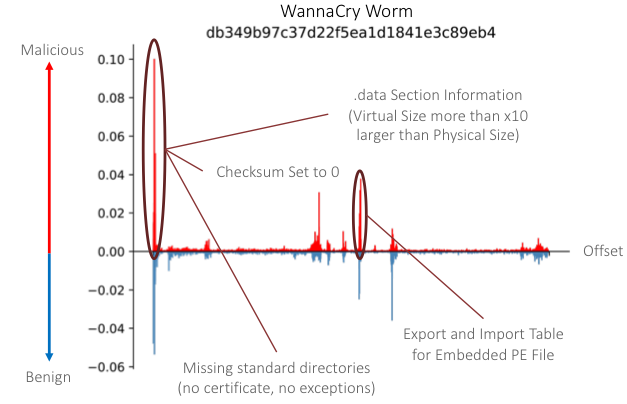
図 6 は、WannaCry ランサムウェア ファミリのワーム アーティファクトのファイル オフセット全体にわたる SHAP 値の分布を示しています。このサンプルで見つかった最も重要な悪意のある機能の多くは、前述のチェックサムやディレクトリ関連の機能など、PE ヘッダー構造に集中しています。ただし、このサンプルの特に興味深い観察結果の 1 つは、別の PE ファイルが埋め込まれていることです。CNN は、これに関連する 2 つのエンドツーエンド機能を発見しました。まず、「.data」セクションの仮想サイズが、セクションの物理サイズの 10 倍以上であることを示すセクション テーブルの領域を特定しました。次に、埋め込まれた PE ファイル自体に悪意のあるインポートとエクスポートが含まれていることを発見しました。全体として、これらの結果は、分類子の深さが、より抽象的な特徴を学習し、下位層のアクティベーションで観察された特定のバイト シーケンスを超えて一般化するのに役立っているように見えることを示しています。
概要
このブログ投稿では、FireEye のバイトベースのディープ ラーニング分類器の内部の仕組みを掘り下げて、それと同様の他のディープ ラーニング分類器が構造化されていない raw バイトからマルウェアについて何を学習しているかを理解します。分析を通じて、分類器の動作、弱点、および強みの多くの重要な側面についての洞察を得ました。
- インポート機能:インポート関連の機能は、CNN アーキテクチャのすべてのレベルでマルウェアを分類する上で大きな役割を果たします。埋め込みレイヤー、低レベルの畳み込み機能、およびエンドツーエンド機能で ASCII ベースのインポート機能の証拠を見つけました。
- 低レベルの命令機能: CNN 分類子の下位層で発見されたいくつかの機能は、特定の種類の関数呼び出しや特定の種類のエクスプロイトを取り巻くコードなど、特定の動作をキャプチャする一連の命令に焦点を当てていました。多くの場合、これらの機能は主にマルウェアに関連していました。これは、低レベルの機能がデータの一般的な側面 (線や単純な形状など) をキャプチャする画像分類など、他のドメインでの CNN の一般的な使用法に反するものです。さらに、これらの低レベル機能の多くは、最も悪意のあるエンド ツー エンド機能には現れませんでした。
- エンド ツー エンドの機能:おそらく、分析の最も興味深い結果は、最も重要な悪意のあるエンド ツー エンドの機能の多くが、従来の ML 分類子から手動で派生した一般的な機能に密接に対応しているということです。証明書の有無、明らかに破損したチェックサム、セクション テーブルの不一致などの機能には、明らかにした下位レベルの機能と明確に類似するものはありません。代わりに、CNN 分類器の深さと複雑さが、特定のバイト シーケンスを意味のある直感的な機能に一般化する上で重要な役割を果たしているようです。
ディープ ラーニングが、持続可能で最先端のマルウェア分類への有望な道筋を提供することは明らかです。同時に、この記事で説明した欠点に対処する実行可能な現実世界のソリューションを作成するには、大幅な改善が必要になります。最も重要な次のステップは、アーキテクチャを改善して、実行可能ファイルを構造化されていないバイト シーケンスとして扱うのではなく、構造的、意味的、および構文的なコンテキストに関するより多くの情報を含めることです。この特殊なドメインの知識をディープ ラーニング アーキテクチャに直接追加することで、分類器は各コンテキストに関連する機能の学習に集中できるようになり、他の方法では不可能な関係を推測し、より優れた一般化を備えたさらに堅牢なエンド ツー エンドの機能を作成できます。プロパティ。
このブログ投稿の内容は、2018 年 10 月 12 ~ 13 日にワシントン DC で開催された情報セキュリティのための応用機械学習会議 (CAMLIS)で発表された研究に基づいています。プレゼンテーションのスライドやビデオなどの追加資料は、会議のウェブサイトで見つけることができます。
このブログ投稿で紹介されている研究の拡張版は、 IEEE Deep Learning and Security ワークショップの査読付き論文で見つけることができます。論文の公開版も利用できます。
参照: https://www.mandiant.com/resources/blog/what-are-deep-neural-networks-learning-about-malware


Comments