
毎日、 Microsoft Defender for Office 365は、何百万ものブランドになりすましメールに遭遇しています。当社のセキュリティ ソリューションは、複数の検出および防止技術を使用して、攻撃者がなりすましの手口を改良し続ける中で、ユーザーが機密情報をフィッシャーに漏らさないようにします。このブログでは、ブランドのなりすまし攻撃の視覚的要素に焦点を当てた別の検出レイヤーの開発に向けた最新のイノベーションについて説明します。このアプローチは、今日のブランドのなりすましを検出するためのシャム ニューラル ネットワークの Black Hat ブリーフィングで紹介しました。
ブランドのなりすまし検出システムをトレーニングして、同じ視覚的要素を使用する正当な電子メールと悪意のある電子メールを区別できるようにする前に、まず、コンテンツが最初にどのブランドを描写しているかを識別するようにシステムに学習させる必要があります。画像を実数に変換し、より小さなデータセットでも正確な判断を実行できる機械学習技術を組み合わせて使用することで、90% のヒット率を維持しながら、すべてのメトリックですべての視覚指紋ベースのベンチマークを上回る検出システムを開発しました。私たちのシステムは単にロゴを「記憶」するのではなく、配色やフォントなどの他の顕著な側面に基づいて決定を下しています。これは、 Microsoft 365 Defenderにフィードする他の最先端の AI の中でも、フィッシング攻撃の長年の問題に対する保護機能を向上させます。
なりすましを特定するための 2 段階のアプローチ
ブランドのなりすまし攻撃では、電子メールや Web サイトは、Microsoft 365 や LinkedIn などの既知の正当なブランドと視覚的に同一に見えるように設計されていますが、パスワードやクレジット カードの詳細など、ユーザーが入力した情報が送信されるドメインは、実際には攻撃者によって制御されています。 Microsoft になりすました悪意のあるサインイン ページの例を図 1 に示します。
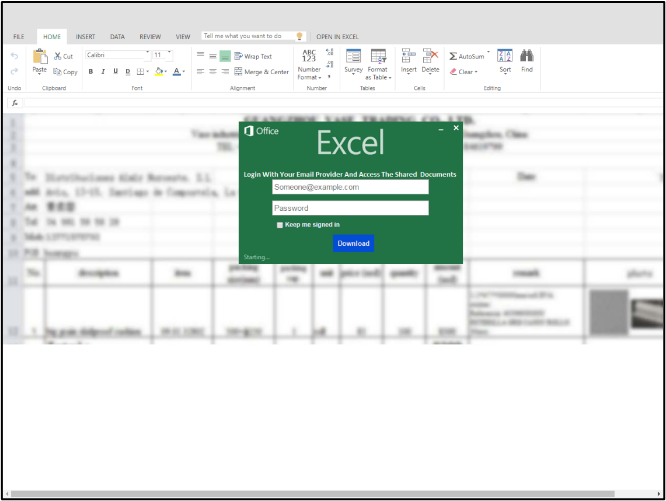
図 1. Microsoft ブランドのなりすましの試みの例
ブランドのなりすまし攻撃を検出する視覚ベースのシステム (コンピューターまたは人間) は、コンテンツの受信時に次の 2 段階のアプローチを取る必要があります。
- コンテンツが既知のブランドのコンテンツに似ているかどうかを判断し、そうである場合はどのブランドかを判断します
- コンテンツに関連付けられた他のアーティファクト (URL、ドメイン名、証明書など) が、特定されたブランドで使用されているものと一致するかどうかを判断します
たとえば、ブランドのなりすまし検出システムが、Microsoft から送信されたように見える画像を検出し、その URL が実際に Microsoft からのものであり、証明書が Microsoft に発行された既知の証明書と一致することを認識した場合、そのコンテンツは正当なものとして分類されます。
ただし、検出器が、図 1 のような正規の Microsoft コンテンツと視覚的特徴を共有するコンテンツに遭遇した場合、そのコンテンツに関連付けられた URL が疑わしい証明書を持つ不明または未分類の URL であることを認識した場合、そのコンテンツはブランドとしてフラグが立てられます。なりすまし攻撃。
ブランドを識別するためのシステムのトレーニング
効果的なブランド偽装検出システムの鍵は、既知のブランドを可能な限り確実に識別することです。これは、手動システムと自動システムの両方に当てはまります。晴眼者にとって、ブランドを識別するプロセスは簡単です。一方、自動化されたシステムにブランドを識別するように教えることは、より困難です。これは、各ブランドが視覚的に異なるサインイン ページを複数持つ場合があるため、特に当てはまります。
たとえば、図 2 は、2 つの Microsoft Excel ブランドのなりすましの試みを示しています。どちらのケースもいくつかの視覚的特徴を共有していますが、背景、色、およびテキストの違いにより、基本的な類似性メトリック (堅牢な画像ハッシュなど) に基づいてブランドを検出するルールベースのシステムを作成することがより困難になります。したがって、私たちの目標は、ブランドのラベル付けを改善することでした。これにより、最終的にブランドのなりすましの検出が改善されます。
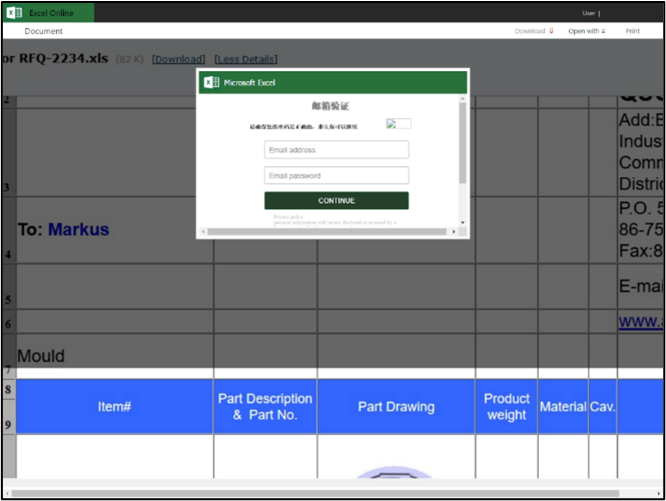
図 2. Microsoft Excel を標的としたブランドのなりすましの試みの別の例
もちろん、ディープ ラーニングは画像認識のデフォルト ツールと想定されているため、ラベル付けされたブランド イメージと最新のディープ ラーニング技術を組み合わせてブランド検出を実行するのは自然なことでした。これを行うために、私たちは最初に独自の爆発システムを使用して、50,000 を超えるブランドのなりすましスクリーンショットを探し、キャプチャし、手動でラベルを付けました。
私たちのデータセットは 1,300 を超えるブランドで構成されていましたが、ほとんどのブランドは十分に表現されていませんでした。 5 回未満の出現は 896 のブランドで、541 のブランドはデータセットに 1 回しか出現しませんでした。各ブランドの重要な表現が不足しているため、畳み込みニューラル ネットワークなどの標準的なアプローチを使用することは現実的ではありませんでした。
埋め込みによる画像の実数への変換
データの限界に対処するために、シャム ニューラル ネットワーク(ニューラル ツイン ネットワークとも呼ばれる) として知られる最先端の少数ショット学習手法を採用しました。ただし、シャム ニューラル ネットワークとは何かを説明する前に、埋め込みベースの分類器がどのように機能するかを理解することが重要です。
埋め込みベースの分類器の構築は、2 つの手順で進めます。最初のステップは、画像を低次元空間に埋め込むことです。これは、分類器が画像を構成するピクセルを実数のベクトルに変換することを意味します。したがって、たとえば、ネットワークは図 1 のピクセル値を入力として受け取り、値 (1.56, 0.844) を出力します。ネットワークはイメージを2 つの実数に変換するため、ネットワークはイメージを 2次元空間に埋め込むと言います。
実際には 2 次元以上の埋め込みを使用しますが、図 3 は 2 次元空間に埋め込まれたすべての画像を示しています。赤い点は、すべて 1 つのブランドのように見える画像の埋め込みを表しています。これにより、ビジュアル データがニューラル ネットワークが消化できるものに効果的に変換されます。
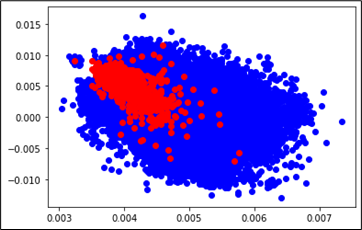
図 3: 埋め込みの 2 次元表現。赤い点は 1 つのブランドを表します
埋め込みが与えられた場合、アルゴリズムの 2 番目のステップは、埋め込まれた画像を分類することです。たとえば、埋め込まれた一連のスクリーンショットと X と呼ばれる新しいスクリーンショットが与えられた場合、X を埋め込んでから、埋め込まれたスペースで X に「最も近い」画像を持つブランドを X に割り当てることで、ブランド分類を実行できます。
コントラスト損失を最小限に抑えるためのシステムのトレーニング
上記の 2 次元の埋め込みを理解する上で、読者は、同じブランドのスクリーンショットを近くに配置する「埋め込みツール」があったか、少なくとも画像が埋め込まれた方法に固有の意味があると考えるかもしれません。もちろん、どちらも真実ではありませんでした。代わりに、これを行うために検出器をトレーニングする必要がありました。
ここで、関連するコントラスト損失を伴うシャム ニューラル ネットワークの出番です。シャム ネットワークは、入力として2 つの生の画像を取り、両方を埋め込みます。ネットワークが計算するコントラスト損失は、画像が同じブランドからのものである場合は画像間の距離であり、異なるブランドからのものである場合は画像間の距離の負の値です。これは、シャム ネットワークが損失を最小限に抑えるように訓練されている場合、同じブランドのスクリーンショットを近くに埋め込み、異なるブランドのスクリーンショットを遠くに埋め込むことを意味します。ネットワークが損失を最小限に抑える方法の例を図 4 に示します。
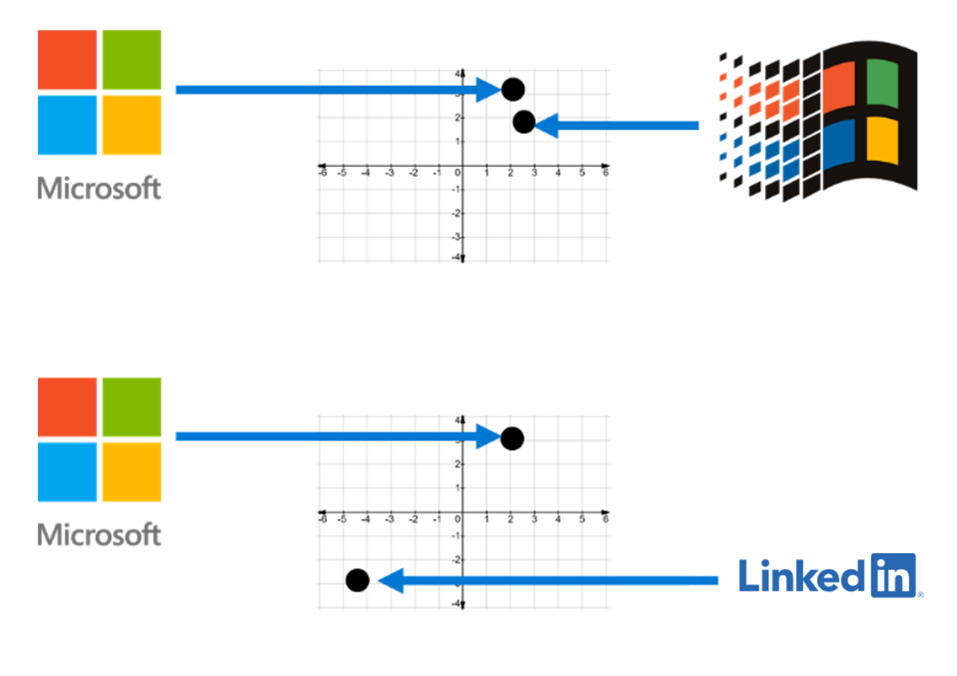
図 4. 成功したシャム ネットワークの埋め込み。このネットワークは、Microsoft に関連するスクリーンショットを近くに埋め込み、同時に Microsoft と LinkedIn のスクリーンショットを遠く離れた場所に埋め込むことで、損失を最小限に抑えます。アルゴリズムは、ロゴだけでなく、スクリーンショット全体でトレーニングされることに注意してください。ここでのロゴは、説明のみを目的として使用されています。
また、シャム ネットワークは、埋め込まれた画像に対してあらゆるタイプの分類を実行できることにも言及しました。したがって、標準のフィードフォワード ニューラル ネットワークを使用して、分類を実行するようにシステムをトレーニングしました。完全なアーキテクチャを下の図 5 に示します。画像はまず、最先端のコンピューター ビジョン アーキテクチャである Swin トランスフォーマーを使用して低次元空間に埋め込まれました。次に、埋め込みを使用してコントラスト損失を計算しました。同時に、埋め込みがフィードフォワード ニューラル ネットワークに供給され、予測されたクラスが出力されました。システムをトレーニングする場合、総損失は、対照的な損失と、両方の分類ネットワークの出力に基づく標準的な対数尤度損失の合計です。
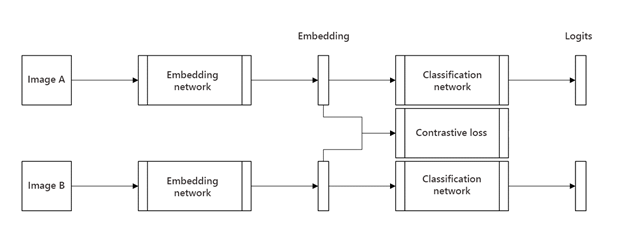
図 5. シャム ニューラル ネットワーク アーキテクチャ
正しいラベル付けのコストと利点に基づく成功指標
これはマルチクラスの分類システムであるため、成功の指標をどのように定義するかについて注意する必要がありました。具体的には、真陽性または偽陰性の概念は、多クラス分類問題では明確に定義されていません。したがって、関連するコストと現実世界の結果の利点に基づいて指標を開発しました。たとえば、既知のブランドを別の既知のブランドとして誤ってラベル付けすることのコストは、これまでに見たことのないブランドを観察することと同じではなく、既知のブランドとしてラベル付けします.さらに、既知のブランドと未知のブランドの指標を分けました。その結果、次の 5 つの指標を開発しました。
- ヒット率 – 正しくラベル付けされた既知のブランドの割合
- 既知の誤分類率 – 別の既知のブランドとして誤ってラベル付けされている既知のブランドの割合
- 不正確な不明率 – 不明なブランドとして誤ってラベル付けされている既知のブランドの割合
- 未知の誤分類率 – 既知のブランドとしてラベル付けされた未知のブランドのスクリーンショットの割合
- 正解不明率 – 正しく不明とラベル付けされた不明ブランドの割合
これらのメトリックは、以下の図 6 にもまとめられています。すべての画像にラベルが付けられているため、トレーニング セットからスクリーンショットが 1 つだけのすべてのブランドを削除して、未知のブランドをシミュレートし、ホールドアウト テスト セットでメトリックを評価するためにのみ使用しました。

図 6.分類指標。上向きの三角形のメトリックは、数値が高いほど結果が良好であることを示します。下向きの三角形のメトリックは、低いほど優れています。
視覚的な指紋ベースのベンチマークを上回るパフォーマンス
当社のブランド偽装分類システムの主な結果を図 7 に示しますが、要約するのは簡単です。当社のシステムは、90% のヒット率を維持しながら、すべてのメトリックですべての視覚的な指紋ベースのベンチマークよりも優れています。また、結果は、ヒット率を最大化する代わりに、既知の誤分類率を最小化する方が有益である場合、ヒット率が 60% を超えたままで、シャム ネットワークがまだ残っている間に、既知の誤分類率を 2% 未満にすることが可能であることも示しています。すべてのメトリックで、視覚的な指紋ベースのアプローチを打ち負かします。
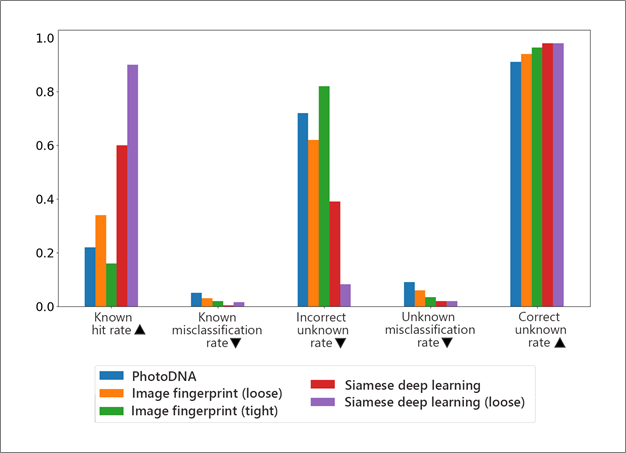
図 7. 私たちのシステムが他の画像認識システムとどのように戦ったかの結果
いくつかの例をさらに調べて、ネットワークが単にスクリーンショットを記憶したのではなく、同じブランドのバリエーションを正しくラベル付けできることを示します。図 8 は、悪意のある 2 つの異なる DHL ブランドのなりすましサインイン ページを示しています。視覚的なレイアウトと配色が異なっていても (左側の画像では黒いバーを使用し、右側の画像では白いバーを使用しています)、ネットワークは両方を正しく分類しました。さらに、下のバーに他社のロゴが複数表示されていても、ネットワークは左側の画像を正しく分類できました。これは、ネットワークが単にロゴを認識したり、配色や主要なフォント スタイルなどの他の機能に基づいて決定したりするだけではないことを意味します。


図 8. DHL サインイン ページのバリエーション。どちらもシステムによって DHL に関連するものとして正しく分類されています。
フィッシング キャンペーンの検出における重要なアプリケーション
フィッシング詐欺師は、フィッシング Web サイトの作成や、既知の正当なブランドに視覚的に非常によく似た電子メールの作成に特に長けています。これにより、ユーザーの信頼を得て、だまして機密情報を開示させることができます。
私たちの仕事は、攻撃者が合法的なブランドのように見えるが、そのブランドの他の既知の特性や機能と一致しないエンティティを検出することで、正当なブランドをハイジャックするのを防ぎます。さらに、この作業は、視覚的にターゲットとする特定のブランドに基づいて既知の攻撃またはフィッシング キットをクラスタリングし、同じブランドになりすまして他の攻撃手法を使用している可能性のある新しい攻撃手法を特定することにより、脅威インテリジェンスの生成に役立ちます。
マイクロソフトの専任研究チームは、脅威インテリジェンスをサポートする AI レイヤーを継続的に改善することで、脅威を常に把握しており、脅威に対する保護と検出の能力に反映されています。 Microsoft Defender for Office 365は、フィッシングなどの電子メールベースの脅威から保護し、セキュリティ運用チームが攻撃を調査して修復できるようにします。 Defender for Office 365 からの脅威データは、 Microsoft 365 Defenderによって分析される信号の品質を向上させ、高度な攻撃に対するクロスドメイン防御を提供できるようにします。
ジャスティン・グラナ、ユチャオ・ダイ、ジュガル・パリフ、ニティン・クマール・ゴエル
Microsoft 365 Defender 研究チーム

Comments