多くのサイバー インシデントは、セキュリティ オペレーション センター (SOC) またはインシデント対応 (IR) チームによって見逃されたか無視された元のアラートにまでさかのぼることができます。ほとんどのアナリストと SOC は用心深く、迅速に対応しますが、実際にはアラートに圧倒されることがよくあります。 SOC が生成するすべてのアラートを確認できない場合、遅かれ早かれ、重要な何かが見過ごされてしまいます。
ここでの中心的な問題はスケーラビリティです。より多くのアナリストを作成するよりも、より多くのアラートを作成する方がはるかに簡単であり、サイバー セキュリティ業界は解決よりもアラートの生成にはるかに優れています。より多くのインテル フィード、より多くのツール、より多くの可視性がすべて、アラートの洪水に加わります。このフラッドを管理するために SOC が実行できることと実行すべきことがあります。たとえば、フォレンジック タスクの自動化 (PCAP のプルとファイルの取得など) を増やしたり、集約フィルターを使用してアラートを同様のバッチにグループ化したりします。これらは効果的な戦略であり、SOC アナリストが実行しなければならない必要なアクションの数を減らすのに役立ちます。ただし、SOC が下す決定は依然として重大なボトルネックとなっています。これは、図 1 の「分析/決定」ブロックです。

このブログ投稿では、このボトルネックを軽減し、SOC の制御を取り戻すのに役立つ機械学習ベースの戦略を提案します。これらの戦略は FireEye Managed Defense SOC に実装されており、アナリストはアラートのトリアージ ワークフロー内でこのアプローチを活用しています。次のセクションでは、データを収集し、アラート分析を取得し、モデルを作成し、有効性ワークフローを構築するプロセスについて説明します。これらはすべて、アラートのトリアージを自動化し、アナリストの時間を解放するという最終的な目標を持っています。
アナリストのリバースエンジニアリング
SOC 環境で発生するすべてのアラートには、アラートが悪意のあるアクティビティを表しているかどうかをアナリストが判断するために使用する特定の情報が含まれています。多くの場合、これらのフォレンジック アーティファクトを経時的に評価する際に使用される、十分に整備された分析プロセスと経路があります。私たちは、SOC オペレーションを真にスケールするために、これらの分析経路を抽出し、それらを横断するように機械をトレーニングし、潜在的に新しい経路を発見できるかどうかを調査したいと考えていました。
SOC は、ラベルのないアラートを入力し、「悪意のある」または「無害」とラベル付けされたアラートを出力する自己完結型のマシンと考えてください。分析をキャプチャし、何かが悪意のあるものであると判断し、その分析を大規模に再現するにはどうすればよいでしょうか?言い換えれば、許容レベルの信頼度の範囲内で、アナリストと同じ分析決定を行うようにマシンをトレーニングできるとしたらどうでしょうか?
基本的な教師ありモデルのプロセス
これに対するデータ サイエンス用語は、「教師あり分類モデル」です。すでに無害または悪意があるとラベル付けされたデータを表示することによって学習するという意味で「教師あり」であり、トレーニングが完了したら、新しい部分を見てほしいという意味で「分類モデル」です。データを収集し、いくつかの個別の結果のいずれかを決定します。この場合、アラートの 2 つの「クラス」 (悪意のあるものと無害なもの) のどちらかを決定するだけです。
このようなモデルの作成を開始するには、データセットを収集する必要があります。このデータセットはモデルの「経験」を形成し、意思決定のためにモデルを「トレーニング」するために使用する情報です。モデルを監視するには、データの各単位に悪意があるか無害であるかのラベルを付ける必要があります。これにより、モデルは各観察結果を評価し、何が悪意のあるもので何が良性であるかを判断し始めることができます。通常、クリーンでラベル付けされたデータセットを収集することは、教師ありモデル パイプラインの最も難しい部分の 1 つです。ただし、当社の SOC の場合、アナリストは毎週何千ものアラートを常にトリアージ (または「ラベル付け」) しているため、クリーンで標準化され、ラベル付けされたアラートが豊富にあることは幸運でした。
ラベル付けされたデータセットが定義されたら、次のステップは、各アラートに存在する情報を表すために使用できる「機能」を定義することです。 「機能」は、情報の一部と考えることができます。たとえば、情報が文字列として表されている場合、自然な「特徴」は文字列の長さである可能性があります。アラート分類モデルの機能を構築する背後にある中心的なアイデアは、アナリストが意思決定を行う際に考慮する可能性のあるすべての側面を表現および記録する方法を見つけることでした。
モデルを構築するには、使用するモデル構造を選択し、利用可能な全データのサブセットでモデルをトレーニングする必要があります。一般に、トレーニング データ セットが大きく多様であるほど、モデルのパフォーマンスは向上します。残りのデータは、トレーニングされたモデルが本当に効果的かどうかを確認するための「テスト セット」として使用されます。このテスト セットを保持することで、これまで見たことがないが、真のラベルがわかっているサンプルでモデルが評価されることが保証されます。
最後に、適切な調整ができるように、モデルの有効性を経時的に評価し、間違いを調査する方法があることを確認することが重要です。評価して再トレーニングするための計画とパイプラインがなければ、モデルのパフォーマンスはほぼ確実に低下します。
機能エンジニアリング
独自のモデルを作成する前に、経験豊富なアナリストにインタビューし、アラートに関する決定を下す前に通常評価する情報を文書化しました。これらのインタビューは、特徴抽出の基礎を形成しました。たとえば、アナリストがアラートを確認するのは「簡単」だと言った場合、次のように尋ねます。そして、その決定を下すのに何が役立ちますか?」分析をキャプチャするために使用できる機能とモデルへの洞察を与えるのは、このようなリバース エンジニアリングです。
たとえば、プロセス実行イベントを考えてみましょう。潜在的に悪意のあるプロセスの実行に関するアラートには、次のフィールドが含まれる場合があります。
- プロセス パス
- プロセス MD5
- 親プロセス
- プロセス コマンドの引数
これは最初は限られた機能空間のように見えるかもしれませんが、これらのフィールドから抽出できる有用な情報がたくさんあります。
たとえば、「C:windowstempm.exe」のプロセス パスから開始すると、アナリストはすぐにいくつかの機能を確認できます。
- プロセスは一時フォルダーに存在します: C:windowstemp
- プロセスは、ファイル システムの 2 つのディレクトリの深さです
- プロセスの実行可能ファイル名は 1 文字です
- プロセスの拡張子は .exe です
- プロセスは「一般的な」プロセス名ではありません
これらは単純に見えるかもしれませんが、膨大な量のデータと例から、これらの情報を抽出することで、モデルがイベントを区別するのに役立ちます。アナリストが行う方法でプロセスを表示するようにモデルに「教える」ためには、成果物の最も基本的な側面でさえキャプチャする必要があります。
次に、特徴は、次のように、より離散的な表現にエンコードされます。
|
Temp_folder |
深さ |
名前_長さ |
拡大 |
common_process_name |
|
真実 |
2 |
1 |
EXE |
間違い |
プロセス実行イベントについて考慮すべきもう 1 つの重要な機能は、親プロセスと子プロセスの組み合わせです。予想される「系統」からの逸脱は、悪意のある活動の強力な指標となる可能性があります。
前述の例の親プロセスが「powershell.exe」であるとします。潜在的な新機能は、親プロセスとプロセス自体の連結から派生する可能性があります: 「powershell.exe_m.exe」。これは、機能的には親子関係の ID として機能し、別の主要な分析アーティファクトをキャプチャします。
ただし、最も豊富なフィールドはおそらくプロセスの引数です。プロセスの引数は独自の種類の言語であり、言語分析は予測分析でよく使われる分野です。
次のようなものを探すことができますが、これらに限定されません。
- ネットワーク接続文字列 (「http://」、「https://」、「ftp://」など)。
- Base64 でエンコードされたコマンド
- レジストリ キーへの参照 (「HKLM」、「HKCU」)
- 難読化の証拠 (ティック、$、セミコロン) (詳細についてはDaniel Bohannon の作品を参照)
これらの特徴とその値がトレーニング データセットにどのように表示されるかによって、モデルが学習する方法が決まります。何千ものアラートにわたる機能の分布に基づいて、機能とラベルの間に関係が生まれ始めます。これらの関係はモデルに記録され、最終的に新しいアラートの予測に影響を与えるために使用されます。トレーニング セット内の特徴の分布を見ると、これらの潜在的な関係のいくつかについて洞察を得ることができます。
たとえば、図 2 は、プロセス コマンド長の分布が、悪意のあるもの (赤) と無害なもの (青) でグループ化したときにどのように表示されるかを示しています。
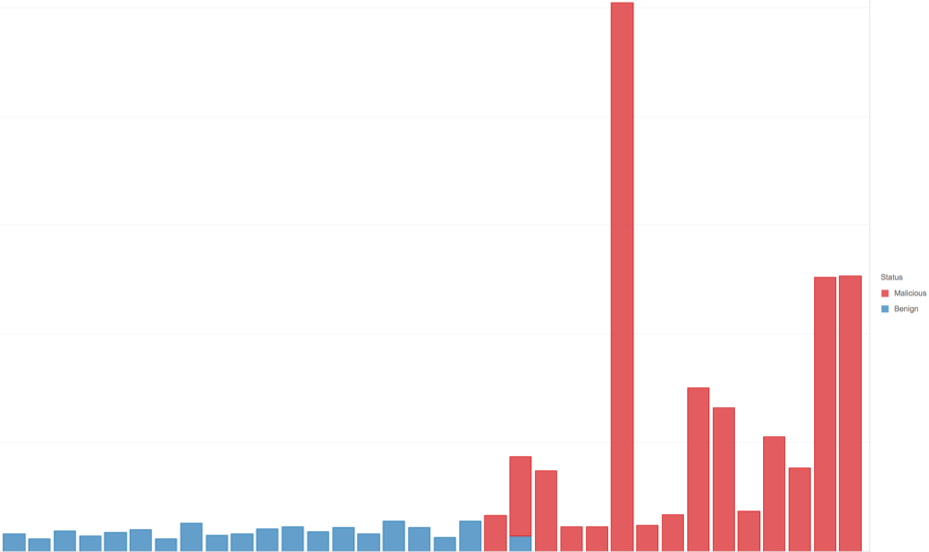
このグラフは、サンプルのサブセットで、コマンドの長さが長いほど悪意のある可能性が高いことを示しています。これは、右側が赤、左側が青で表されます。ただし、プロセスの長さだけが要因ではありません。
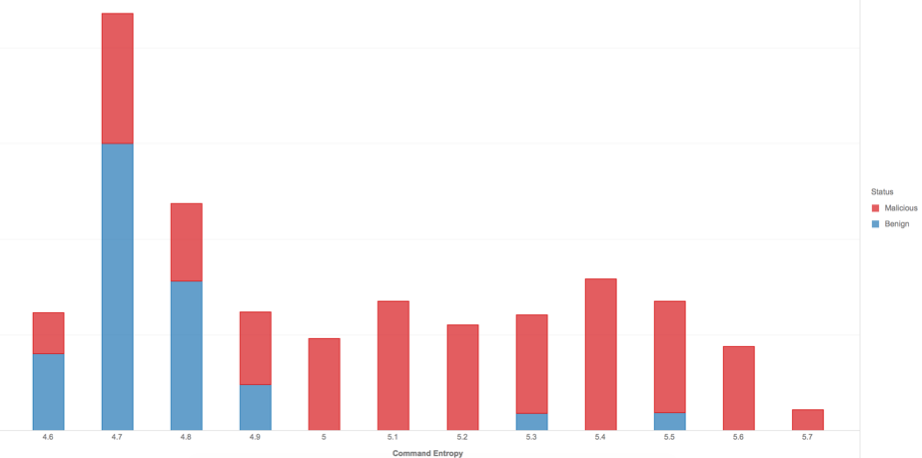
私たちの機能セットの一部として、各コマンドの「複雑さ」を概算することも役立つと考えました。このために、文字列に存在するランダム性の程度を測定する一般的に使用される指標である「シャノン エントロピー」を使用しました。
図 3 は、コマンド エントロピーの分布を悪意のあるものと無害なものに分けて示しています。クラスが完全に分離されているわけではありませんが、このデータ サンプルでは、エントロピーが高いサンプルほど一般的に悪意のある可能性が高いことがわかります。
モデルの選択と一般化
データセット全体の特徴が生成されたら、それらを使用してモデルをトレーニングします。最適なモデルを選択するための完全な手順はありませんが、データ内の特徴のタイプを調べることで、モデルを絞り込むことができます。プロセス イベントの場合、文字列と数値として表される機能の組み合わせがあります。アナリストは各アーティファクトを評価するときに、これらの各機能について質問し、その回答を組み合わせて、プロセスが悪意のある可能性を推定します。
私たちのユースケースでは、「解釈可能な」モデル、つまりアーティファクトについて特定の決定を下した理由をより簡単に明らかにできるモデルを優先することも理にかなっています。このようにして、アナリストはモデルに対する信頼を築き、モデルが犯している分析上の誤りを検出して修正することができます。データの性質、アナリストが下す意思決定、および解釈可能性への要望を考えると、意思決定ツリー ベースのモデルがアラートの分類に適していると感じました。
デシジョン ツリーについて学ぶために公開されているリソースは数多くありますが、デシジョン ツリーの背後にある基本的な直感は、決定木は反復プロセスであり、一連の質問をして非常に信頼できる答えにたどり着こうとするということです。 「Twenty Questions」というゲームをプレイしたことがある人なら誰でも、このコンセプトに精通しています。最初に、可能性を排除するために一般的な質問が行われ、次に、可能性を絞り込むためのより具体的な質問が行われます。十分な数の質問と回答がなされた後、「質問者」は正しい答えを推測する可能性が高いと感じます。
図 4 は、プロセスの実行を評価するために使用できる意思決定ツリーの例を示しています。
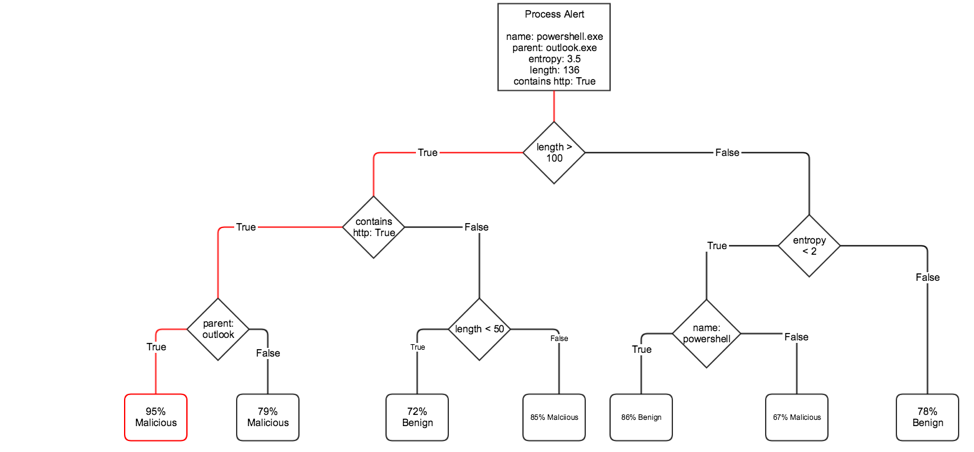
図のアラートの例では、「決定パス」が赤でマークされています。これが、この決定木モデルが予測を行う方法です。最初に、「長さは 100 文字を超えていますか?」と尋ねます。含まれている場合は、次の質問「文字列 ‘http’ が含まれていますか?」に進みます。というように、知識に基づいた推測を自信を持って行えるようになるまで続けます。図 4 の例では、この決定パスを通過するすべてのトレーニング アラートの 95% が悪意のあるものであったと仮定すると、モデルは、このアラートが悪意のあるものである可能性を 95% 予測します。
このような詳細な組み合わせの質問をすることができるため、決定木が「オーバーフィット」したり、トレーニング セットに密接に結びついたルールを学習したりする可能性があります。これにより、モデルが新しいデータに「一般化」する能力が低下します。この影響を軽減する 1 つの方法は、わずかに異なる多くの決定木を使用し、それぞれに結果を「投票」させることです。このデシジョン ツリーの「アンサンブル」はランダム フォレストと呼ばれ、実際にデプロイされたモデルのパフォーマンスを向上させることができます。これが、モデルに最終的に選択したアルゴリズムです。
SOC アラート モデルのしくみ
新しいアラートが表示されると、成果物内のデータは、モデルのトレーニングに使用される特徴表現と同じ構造を持つ、エンコードされた特徴のベクトルに変換されます。次に、モデルはこの「特徴ベクトル」を評価し、予測されたラベルの信頼レベルを適用します。設定したしきい値に基づいて、アラートを悪意のあるものと無害なものに分類できます。

例として、図 5 に示すイベントは、次の特徴値を作成する可能性があります。
- 親プロセス: ‘wscript’
- コマンドエントロピー: 5.08
- コマンド長 = 103
トレーニング方法に基づいて、モデル内のツリーはそれぞれ、新しい特徴ベクトルに関する一連の質問をします。特徴ベクトルが各ツリーをトラバースすると、最終的に最終的な「リーフ」に収束し、良性または悪意のあるものとして分類されます。次に、各ツリーによって行われた集約された決定を評価して、ベクトル内のどの機能が最終的な分類で最大の役割を果たしたかを推定できます。
次に、SOC のアナリスト向けに、モデルから抽出された機能を提示し、データセット全体でのそれらの機能の分布を示します。これにより、アナリストは、モデルが何を考えた「理由」と、私たちが確認したすべてのアラートでそれらの機能がどのように表現されているかについての洞察を得ることができます。たとえば、このアラートの「説明」は次のようになります。
- コマンド エントロピー = 5.08 > 4.60: 51.73% 脅威
- occuranceOfChar “”= 9.00 > 4.50: 64.09% 脅威
- occuranceOfChar:“)” (=0.00) <= 0.50: 78.69% 脅威
- processTree=”cmd.exe_to_cscript.exe” ではない: 99.6% の脅威
したがって、分析時に、アナリストはイベントの生データ、モデルからの予測、意思決定パスの概算、および機能全体の重要度の単純化された解釈可能なビューを確認できます。
SOC によるモデルの使用方法
結論に到達するためにモデルが使用した機能を表示することで、経験豊富なアナリストは自分のアプローチをモデルと比較し、モデルが何か間違ったことをしている場合にフィードバックを提供できます。逆に、新しいアナリストは、親子関係、難読化の兆候、引数内のネットワーク接続文字列など、見落としていた可能性のある機能に注目することを学ぶかもしれません。結局のところ、モデルは何千ものアラートを超えるすべてのアナリストの集合的な経験から学習しています。したがって、このモデルは、アナリストの経験の集約を SOCに反映する実用的なリフレクションを提供し、各アナリストが同僚から推移的に学習できるようにします。
さらに、モデルの出力をパラメーターとして使用してルールを作成することもできます。モデルがアラートのサブセットに対して特に自信を持っており、SOC がその脅威のファミリーを自動的に分類することに満足している場合、次のようなルールを単純に記述することができます。そして、モデルの信頼度が 99 を超えている場合、このアラートは自動的に不良と見なされ、レポートが生成されます。」または、偽陽性の可能性が高い場合は、10 未満のモデル スコアを使用して偽陽性の群れを選別するルールを作成できます。
モデルの有効性を維持する方法
モデルがトレーニングされた日、モデルは学習を停止します。しかし、脅威、つまりアラートは常に進化しています。したがって、新しいアラート データを使用してモデルを継続的に再トレーニングし、環境の変化から学習し続けることが不可欠です。
さらに、モデルの全体的な有効性を経時的に監視することが重要です。モデルの結果をアナリストのフィードバックと比較するための有効性分析パイプラインを構築すると、モデルがドリフトし始めているか、構造的なバイアスが発生しているかを特定するのに役立ちます。アナリストのフィードバックを評価して取り入れることも、特定の誤分類を特定して対処し、必要になる可能性のある新しい機能を発見するために重要です。
これらの目標を達成するために、新しくラベル付けされたイベントでトレーニング データベースを更新するバックグラウンド ジョブを実行します。アラートが増えるにつれて、新しい観察結果でモデルを定期的に再トレーニングします。精度の問題が発生した場合は、診断して対処します。再トレーニングされたモデルの全体的な精度スコアに満足したら、モデル オブジェクトを保存し、そのモデル バージョンの使用を開始します。
また、モデルが間違っている場合にアナリストが記録するためのフィードバック メカニズムも提供します。アナリストは、モデルによって提供されるラベルと説明を確認できますが、独自の決定を下すこともできます。モデルに同意するかどうかに関係なく、インターフェイスを介して独自のラベルを入力できます。アナリストから提供されたこのラベルは、説明に関してアナリストから提供されたオプションの説明とともに保存されます。
最後に、これらの手動ラベルはさらに評価が必要な場合があることに注意してください。例として、ネットワーク コマンド アンド コントロール通信がシンクホールされたコモディティ マルウェア アラートを考えてみましょう。アナリストはアラートを評価し、PCAP サンプルを含むトリアージの詳細を引き出し、マルウェアが実行されている間、環境に対する真の脅威が軽減されたことを確認できます。差し迫った脅威ではないため、アナリストはこのアラートを「無害」とマークする場合があります。ただし、シンクホールが発生したという事実は、実行のアーティファクトがまだ悪意のあるアクティビティを表していることに変わりはありません。さまざまな状況下で、この感染は組織に悪影響を及ぼした可能性があります。ただし、モデルを再トレーニングするときに無害なラベルが使用されると、本質的に悪意のあるものは実際には無害であり、将来的に偽陰性につながる可能性があることをモデルに教えてしまいます。
有効性を経時的に監視し、新しいアラートでモデルを更新および再トレーニングし、手動のアナリスト フィードバックを評価することで、モデルのパフォーマンスと経時的な学習を可視化できます。最終的に、これはモデルの信頼性を高めるのに役立つため、より多くのタスクを自動化し、アナリストがハンティングや調査などのタスクを実行する時間を解放できます。
結論
教師あり学習モデルは、経験豊富なアナリストに取って代わるものではありません。ただし、予測分析と機械学習を SOC ワークフローに組み込むことで、アナリストの生産性を高め、時間を解放し、真に専門知識を必要とする脅威に対して調査スキルと創造性を確実に活用することができます。
このブログ投稿では、SOC のアラート分類モデルを構築する際の主要なコンポーネントと考慮事項について概説しています。このようなモデルを構築する際には、データ収集、ラベリング、機能生成、モデル トレーニング、有効性分析のすべてを慎重に検討する必要があります。ファイア・アイは、この調査を繰り返して、検出および対応能力を向上させ、製品の検出効率を継続的に改善し、最終的にクライアントを保護します。
この投稿で説明されているプロセスと例は、単なる調査ではありません。 FireEye Managed Defense SOC 内では、前述のプロセスを使用して構築されたアラート分類モデルを使用して効率を高め、アナリストの専門知識を最も必要な場所に適用できるようにしています。脅威とアラートが増え続ける世界では、SOC の効率性を向上させることが、重大な侵入を見逃すか捕らえるかの違いを意味する可能性があります。
謝辞
Seth Summersett と Clara Brooks に心から感謝します。
***
FireEye ICE データ サイエンス チームは、高度な訓練を受けたデータ サイエンティストとエンジニアからなる少人数のチームであり、アナリスト、製品、および顧客に影響力のある機能を提供することに重点を置いています。 ICE-DS は、サイバーセキュリティにおける困難な問題の研究と解決に関心のある優秀な候補者を常に探しています。興味のある方は、 Mandiant のキャリアをご覧ください。
参照: https://www.mandiant.com/resources/blog/build-machine-learning-models-for-the-soc


Comments