このブログ記事では、エンドポイントでの難読化された Windows コマンド ライン呼び出しを検出するという、新たなセキュリティ問題を解決するための機械学習 (ML) アプローチを紹介します。この比較的新しい脅威機能の紹介から始めて、そのような問題が従来どのように処理されてきたかについて説明します。次に、この問題を解決するための機械学習のアプローチについて説明し、ML が堅牢な難読化検出器の開発と保守を大幅に簡素化する方法を指摘します。最後に、2 つの異なる ML 手法を使用して得られた結果を提示し、それぞれの利点を比較します。
序章
悪意のあるアクターは、感染ワークフローの一部として PowerShell や Windows コマンド プロセッサ (cmd.exe) などの組み込みユーティリティを使用して、検出の可能性を最小限に抑え、ホワイトリストによる防御戦略をバイパスすることで、ますます「土地を離れて生活する」ようになっています。新しい難読化ツールのリリースにより、目に見える構文とコマンドの最終的な動作との間に間接的なレイヤーが追加されるため、これらの脅威の検出がさらに困難になります。たとえば、 Invoke-Obfuscationと Invoke-DOSfuscation は、それぞれ Powershell と Windows コマンド ラインの難読化を自動化する最近リリースされた 2 つのツールです。
難読化を検出するための従来のパターン マッチングとルールベースのアプローチは、開発と一般化が困難であり、防御側にとってメンテナンスの大きな頭痛の種になる可能性があります。 ML 手法を使用してこの問題に対処する方法を示します。
難読化されたコマンド ラインの検出は、悪意のある可能性のあるアクティビティに対して強力なフィルターを提供することで、防御側が確認しなければならないデータを減らすことができるため、非常に便利な手法です。実際には「正当な」難読化の例がいくつかありますが、ほとんどの場合、難読化の存在は一般的に悪意のシグナルとして機能します。
バックグラウンド
悪意のあるペイロードの暗号化 ( Cascade ウイルスから始まる) や文字列の難読化、 JavaScript の難読化など、マルウェアの存在を隠すために難読化が採用されてきた長い歴史があります。難読化の目的は 2 つあります。
- 実行可能コード、文字列、またはスクリプト内のパターンを見つけにくくし、防御ソフトウェアによって簡単に検出できるようにします。
- リバース エンジニアやアナリストがマルウェアの動作を解読して完全に理解することを困難にします。
その意味では、コマンド ラインの難読化は新しい問題ではなく、 難読化の対象(Windows コマンド プロセッサ) が比較的新しいというだけです。 Invoke-Obfuscation (PowerShell 用) や Invoke-DOSfuscation (cmd.exe 用) などのツールの最近のリリースは、これらのコマンドがいかに柔軟であるか、そして信じられないほど複雑な難読化でもコマンドを効果的に実行できることを示しています。
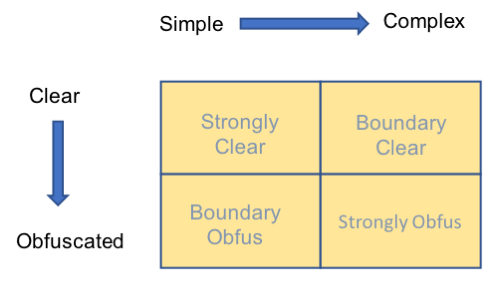
難読化されたコマンド ラインと難読化されていないコマンド ラインの空間には、単純/複雑および明確/難読化の 2 つのカテゴリ軸があります (図 1 と図 2 を参照)。この説明では、「単純」とは、一般に短く比較的単純ですが、難読化を含めることができることを意味します。一方、「複雑」とは、難読化されているかどうかに関係なく、長くて複雑な文字列を意味します。したがって、単純/複雑な軸は、難読化された/難読化されていない軸と直交しています。これら 2 つの軸の相互作用により、スクリプトが難読化されているかどうか (コマンドの長さなど) を検出するための単純なヒューリスティックが、難読化されていないサンプルで誤検知を生成する多くの境界ケースが生成されます。コマンド ライン プロセッサの柔軟性により、ML の観点から分類は困難なタスクになります。


従来の難読化検出
従来の難読化検出は、3 つのアプローチに分けることができます。 1 つの方法は、Windows コマンド ラインの最も一般的に乱用される構文に一致するように、多数の複雑な正規表現を記述することです。図 3 は、不明瞭化で見られる一般的なパターンである call コマンドとアンパサンド チェーンを一致させようとする正規表現の 1 つを示しています。図 4 は、この正規表現が検出するように設計されたコマンド シーケンスの例を示しています。
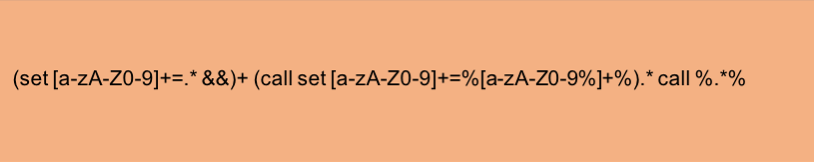

このアプローチには 2 つの問題があります。第 1 に、コマンド ラインの悪用の可能性をすべてカバーする正規表現を開発することは事実上不可能です。コマンド ラインの柔軟性により、正規表現を使用して表現することは可能ですが非現実的な非正規言語になります。このアプローチの 2 つ目の問題は、悪意のあるサンプルが使用している手法に正規表現が存在する場合でも、攻撃者は正規表現を回避するためにマイナーな変更を加えることができるということです。図 5 は、図 4 のシーケンスを少し変更したもので、正規表現の検出を回避しています。
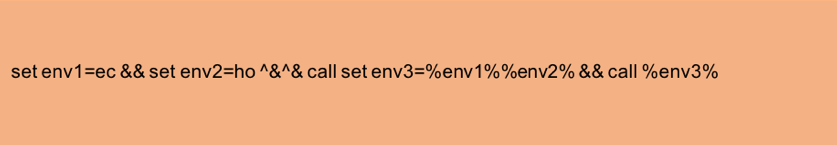
ML アプローチに近い 2 番目のアプローチでは、複雑な if-then ルールを記述します。ただし、これらのルールは導き出すのが難しく、検証が複雑であり、作成者がそのようなルールによる検出を逃れるように進化するにつれて、メンテナンスの負担が大きくなります。図 6 は、そのような if-then ルールの 1 つを示しています。
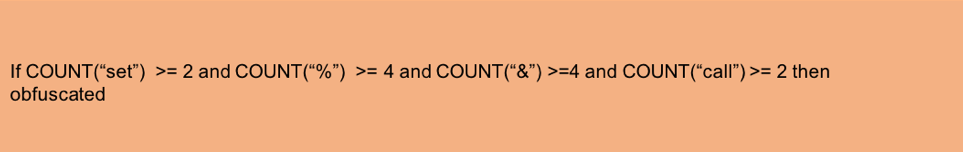
3 番目のアプローチは、正規表現と if-then ルールを組み合わせることです。これは、開発と保守の負担を非常に複雑にし、最初の 2 つのアプローチを脆弱にするのと同じ弱点に悩まされています。図 7 は、正規表現を使用した if-then ルールの例を示しています。明らかに、そのようなルールの有効性を生成、テスト、維持、および決定することがいかに面倒であるかを理解するのは簡単です.
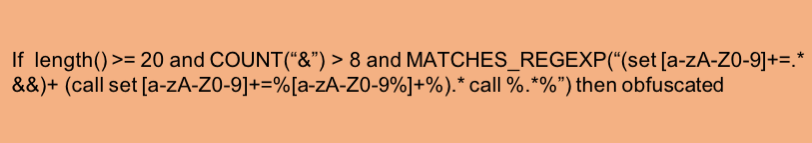
ML アプローチ – パターン マッチングとルールの先へ
ML を使用すると、これらの問題の解決が簡素化されます。機能ベースのアプローチと機能のないエンドツーエンドのアプローチの 2 つの ML アプローチについて説明します。
あらゆる種類の生データ (数値である場合) で機能する ML 手法がいくつかあり、ニューラル ネットワークはその代表的な例です。他のほとんどの ML アルゴリズムでは、モデラーが特徴と呼ばれる関連情報を生データから抽出してからアルゴリズムに入力する必要があります。この後者のタイプのいくつかの例は、ツリーベースのアルゴリズムであり、このブログでも取り上げます ( ツリーベースのアルゴリズムの構造と使用法については、以前のブログ投稿で説明し、勾配ブースト ツリーベース モデルを使用しました)。 )。
ML の基礎 – ニューラル ネットワーク
ニューラル ネットワークは、最近非常に人気が高まっている ML アルゴリズムの一種であり、ニューロンと呼ばれる一連の要素で構成されています。ニューロンは基本的に、一連の入力を受け取り、これらの入力の加重合計を計算し、その合計を非線形関数に入力する要素です。ニューロンの比較的浅いネットワークは、入力と出力の間の連続的なマッピングを近似できることが示されています。この研究に使用した特定のタイプのニューラル ネットワークは、畳み込みニューラル ネットワーク (CNN) と呼ばれるもので、主にコンピューター ビジョン アプリケーション用に開発されましたが、自然言語処理を含む他の分野でも成功を収めています。ニューラル ネットワークの主な利点の 1 つは、機能を手動で設計しなくてもトレーニングできることです。
特徴のない ML
ニューラル ネットワークは特徴データで使用できますが、このアプローチの魅力の 1 つは、特徴の設計や抽出を行わずに (数値形式に変換された)生データを処理できることです。モデルの最初のステップは、テキスト データを数値形式に変換することです。各文字タイプが実数値でエンコードされる文字ベースのエンコードを使用しました。値はトレーニング中に自動的に導出され、cmd.exe 構文に適用される文字間の関係に関するセマンティック情報を伝達します。
機能ベースの ML
また、手作業で設計された機能と勾配ブースト デシジョン ツリー アルゴリズムも試しました。このモデル用に開発された機能は、文字セットとキーワードの存在と頻度から導き出された、本質的に大部分が統計的でした。たとえば、多数の「%」文字または長く連続した文字列の存在は、潜在的な難読化の検出に寄与する可能性があります。単一の機能によって 2 つのクラスが完全に分離されるわけではありませんが、ツリーベースのモデルに存在する機能の組み合わせにより、データ内の柔軟なパターンを学習できます。これらのパターンは堅牢であり、将来の難読化バリアントに一般化できることが期待されます。
データと実験
モデルを開発するために、数万のエンドポイント イベントから難読化されていないデータを収集し、Invoke-DOSfuscation のさまざまな方法を使用して難読化されたデータを生成しました。データの約 80% をトレーニング データとして使用してモデルを開発し、残りの 20% でテストしました。トレーニングとテストの分割が階層化されていることを確認しました。機能のない ML (つまり、ニューラル ネットワーク) の場合、Unicode コード ポイントを CNN モデルの最初のレイヤーに入力するだけです。最初のレイヤーは、コード ポイントを意味的に意味のある数値表現 (埋め込みと呼ばれる) に変換してから、残りのニューラル ネットワークに供給します。
勾配ブースト ツリー法では、生のコマンド ラインから多数の機能を生成しました。以下はその一部です。
- コマンドラインの長さ
- コマンドラインのキャレットの数
- パイプ記号の数
- コマンドラインの空白の割合
- 特殊文字の割合
- 文字列のエントロピー
- コマンドラインでの文字列「cmd」と「power」の頻度
これらの各機能は個別には弱い信号であり、単独で適切な識別器になることはできませんが、これらの機能を備えた十分なデータでトレーニングされた勾配ブースト ツリーなどの柔軟な分類器は、難読化されたコマンドと難読化されていないコマンドを分類できます。前述の困難にもかかわらず、ライン。
結果
テスト セットに対して評価したところ、勾配ブースト ツリーとニューラル ネットワーク モデルからほぼ同じ結果を得ることができました。
GBT モデルの結果は、F1 スコア、適合率、再現率などの指標がすべて 1.0 に近く、ほぼ完璧でした。 CNN モデルの精度はわずかに劣っていました。
現実世界のシナリオで完全な結果が得られることは確かに期待できませんが、それでもなお、これらのラボの結果は心強いものでした.難読化されたすべての例は、Invoke-DOSfuscation ツールという 1 つのソースによって生成されたことを思い出してください。 Invoke-DOSfuscation はさまざまな難読化されたサンプルを生成しますが、現実の世界では、Invoke-DOSfuscation が生成するサンプルとはまったく異なるサンプルが少なくともいくつか見られると予想されます。現在、実際の悪意のある攻撃者からの難読化されたサンプルでこのモデルの一般化可能性をより正確に把握するために、現実世界の難読化されたコマンド ラインを収集しています。コマンドの難読化は、それ以前の PowerShell の難読化と同様に、新しいマルウェア ファミリで引き続き出現すると予想されます。
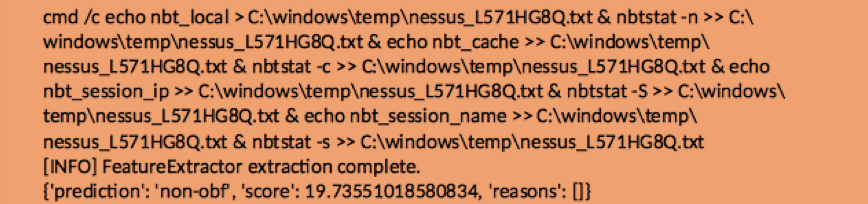
追加のテストとして、Daniel Bohannon (Windows コマンド ライン難読化ツール Invoke-DOSfuscation の作成者) に難読化されたサンプルを作成するよう依頼しました。彼の経験では、従来の難読化検出器では困難でした。いずれの場合も、ML 検出器は難読化を検出できました。いくつかの例を図 8 に示します。

また、Windows コマンド ラインは有効で難読化されていませんが、人間の観察者にはわずかに難読化されているように見える非常に謎めいたテキストも作成しました。これは、境界例を使用して検出器の有効性をテストするために行われました。この場合も、検出器はテキストを難読化されていないものとして正しく分類できました。図 9 は、そのような例の 1 つを示しています。

最後に、図 10 は複雑でありながら難読化されていないコマンド ラインを示しています。このコマンド ラインは、難読化検出器によって正しく分類されますが、統計的特徴に基づいて非 ML 検出器をだます可能性があります (たとえば、手作りの重み付けスキームを備えたルールベースの検出器)。特殊文字の割合、コマンド ラインの長さ、コマンド ラインのエントロピーなどの機能を使用したしきい値)。
CNN 対 GBT の結果
慎重に選択された機能を使用して構築された、大幅に調整された GBT 分類器の結果を、生データ (機能のない ML) でトレーニングされた CNN の結果と比較しました。 CNN アーキテクチャは大幅に調整されていませんでしたが、興味深いことに、図 10 のようなサンプルでは、GBT 分類子は 19.7% のスコアで難読化されていないことを自信を持って予測しました (非難読化に対する分類子の信頼度の尺度の補数)。 -難読化)。一方、CNN 分類器は、50% の信頼確率で難読化されていないものを予測しました。これは、難読化されたものと難読化されていないものの境界にあるものです。 CNN モデルの誤分類の数も、Gradient Boosted Tree モデルの誤分類より多くなりました。これらは両方とも、CNN の不適切な調整の結果である可能性が最も高く、機能のないアプローチの根本的な欠点ではありません。
結論
このブログ投稿では、難読化された Windows コマンド ラインを検出するための ML アプローチについて説明しました。これは、悪意のあるコマンド ラインの使用を特定するためのシグナルとして使用できます。 ML 手法を使用して、複雑な if-then ルールと正規表現を維持するという不適切でコストのかかる手法に頼ることなく、このようなコマンド ラインを検出するための非常に正確なメカニズムを示しました。より包括的な ML アプローチは、難読化の新しいバリエーションをキャッチするのに十分な柔軟性を備えています。ギャップが検出された場合、通常は、適切に選択された回避者のサンプルをトレーニング セットに追加し、モデルを再トレーニングすることで対処できます。
この ML の適用の成功は、コンピューター セキュリティの問題に対する複雑な手動またはプログラムによるアプローチに取って代わる ML の有用性を示すもう 1 つのデモンストレーションです。今後数年間で、ML は FireEye とその他のサイバー セキュリティ業界の両方でますます重要な役割を果たすと予想されます。
参照: https://www.mandiant.com/resources/blog/obfuscated-command-line-detection-using-machine-learning


Comments