
歴史
リッチ テキスト形式 (RTF) は、Microsoft によって開発されたドキュメント形式で、29 年以上にわたってさまざまなプラットフォームで広く使用されてきました。 RTF 形式は非常に柔軟であるため、複雑です。これにより、安全な RTF パーサーの開発が困難になります。 CVE-2010-3333やCVE- 2014-1761 などの悪名高い脆弱性は、RTF 解析ロジックの実装エラーが原因でした。
実際、RTF マルウェアは、RTF 解析の脆弱性を悪用するだけではありません。 RTF は OLE オブジェクトや画像などのオブジェクトの埋め込みをサポートしているため、悪意のある RTF ファイルには、RTF パーサーに関係のない他の脆弱性が含まれている可能性があります。 CVE-2012-0158とCVE-2015-1641は、このような脆弱性の 2 つの典型的な例です。これらの根本原因は RTF パーサーに存在せず、攻撃者は DOC や DOCX などの他のファイル形式を介してこれらの脆弱性を悪用できます。
別のタイプの RTF マルウェアは、脆弱性を使用しません。悪意のある実行可能ファイルが埋め込まれているだけで、ユーザーをだましてそれらの悪意のあるファイルを起動させます。これにより、攻撃者は電子メールを介してマルウェアを配布できますが、これは通常、実行可能ファイルを直接送信するためのベクトルではありません。
RTF は難読化に適した形式であるため、多くのマルウェア作成者は RTF を攻撃ベクトルとして使用することを好みます。そのため、マルウェアは、YARA や Snort などの静的シグネチャ ベースの検出を簡単に回避できます。これが、このスクリプト可能なエクスプロイトの時代にあっても、大量の RTF ベースの攻撃が見られる大きな理由です。
このブログでは、悪意のある RTF で使用される一般的な回避策を紹介します。
一般的な難読化
いくつかの異なる RTF 難読化戦略について説明しましょう。
1. CVE-2010-3333
2009 年に Team509 によって報告されたこの脆弱性は、典型的なスタック オーバーフロー バグです。この脆弱性の悪用は非常に簡単で信頼性が高いため、発見から 7 年経った今でも実際に使用されています。最近、この脆弱性を悪用する攻撃者が、インドの大使を標的にしました。
この脆弱性の根本的な原因は、Microsoft RTF パーサーが pFragments 形状プロパティを解析する手順でスタックベースのバッファ オーバーフローを持っていることです。この脆弱性を悪用するために悪意のある RTF を作成すると、攻撃者は任意のコードを実行できます。その後、Microsoft はこの脆弱性に対処しましたが、多くの古いバージョンの Microsoft Office が影響を受けたため、その脅威率は非常に高くなりました。

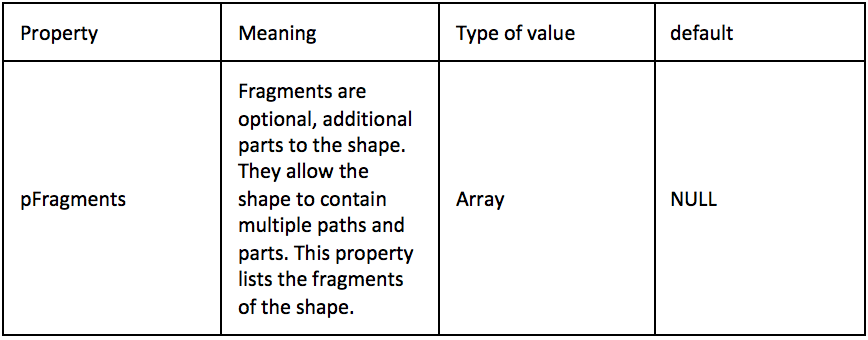
Microsoft Office RTF パーサーには、ソース データを限られたスタックベースのバッファーにコピーする際の適切な境界チェックがありません。このエクスプロイトのパターンは、次のように単純化できます。
|
{rtf1{shp{sp{sn pFragments}{sv A;B;[単語1][単語2][単語3][16進値配列]}}}} |
pFragments は通常の RTF ファイルではめったに見られないため、多くの企業は、YARA または Snort ルールを使用してエクスプロイトを検出するために、sv の直後にこのキーワードと特大の数字を検出するだけです。この方法は、Metasploit によって生成されたサンプルなど、難読化されていないサンプルに対して機能します。ただし、野生のサンプルに対しては、そのような署名ベースの検出は不十分です。たとえば、インド大使を標的にした悪意のある RTFは、署名ベースの検出の欠点を示す良い例です。図 1 は、この RTF ドキュメントを 16 進エディターで表示したものです。スペースの制限のため、図 1 を簡略化しました。最初のサンプルには { } などのダミー記号がたくさんありました。

ご覧のとおり、pFragments キーワードは多くの部分に分割されており、ほとんどのシグネチャ ベースの検出を回避できます。たとえば、ほとんどのウイルス対策製品は、VirusTotal への最初の送信時にこのサンプルを検出できませんでした。実際、sn の分割された部分が結合されるだけでなく、sv の部分も結合されます。次の例は、この難読化を示しています。
|
難読化 |
{rtf1{shp{sp{sn2 pF}{sn44 断片}{sv 1;28}{sv ;ffffffffffffff….}}}} |
|
クリア |
{rtf1{shp{sp{sn pFragments}{sv 1;28 ;ffffffffffffff….}}}} |
静的署名ベースの検出を無効にするために、前述のサンプルとは異なるさまざまなアイデアを考え出すことができます。
‘x0D’ と ‘x0A’ が混在していることに注意してください。これらは ‘r’ と ‘n’ であり、RTF パーサーは単にそれらを無視します。
2.埋め込みオブジェクト
ユーザーは、OLE (Object Linking and Embedding) コントロール オブジェクトなど、さまざまなオブジェクトを RTF に埋め込むことができます。これにより、CVE-2012-0158 や CVE-2015-1641 などの OLE 関連の脆弱性を RTF ファイルに収めることができます。エクスプロイトに加えて、PE、CPL、VBS、JS などの実行可能ファイルが RTF ファイルに埋め込まれていることも珍しくありません。これらのファイルには、ユーザーをだまして埋め込みオブジェクトを起動させるために、何らかの形式のソーシャル エンジニアリングが必要です。 RTF ドキュメント内に PE ファイルを埋め込むデータ損失防止 (DLP) ソリューションも見られます。ユーザーの悪い習慣を助長するため、これは悪い習慣です。
最初に埋め込みオブジェクトの構文を見てみましょう:

<objtype> は、オブジェクトのタイプを指定します。 objocx は、悪意のある RTF で OLE コントロール オブジェクトを埋め込むために使用される最も一般的なタイプです。そのため、例として取り上げましょう。 objdata の直後のデータは、次のように定義されたOLE1 ネイティブ データです。
|
<データ> |
(binN #BDATA) | #SDATA |
|
#BDATA |
バイナリデータ |
|
#SDATA |
16 進データ |
攻撃者は、さまざまな要素を <data> に挿入して、静的シグネチャの検出を回避しようとします。これらのトリックを理解するために、いくつかの例を見てみましょう。
を。たとえば、binN は #SDATA と交換できます。 binN の直後のデータは生のバイナリ データです。次の例では、数値 123 がバイナリ データとして扱われるため、メモリ内で 16 進値 313233 に変換されます。
|
難読化 |
{objectobjocxobjdatabin3 123} |
|
クリア |
{objectobjocxobjdata 313233} |
別の例を見てみましょう。
|
難読化 |
{objectobjocxobjdatabin41541544011100001100000000000000000000000000000000000000003 123} |
|
クリア |
{objectobjocxobjdata 313233} |
上記の表で赤でマークされた数値パラメーター文字列を使用して atoi または atol を呼び出そうとすると、実際の値は 3 であるはずなのに、0x7fffffff が返されます。
これは、 bin が 32 ビットの符号付き整数の数値パラメーターを取るために発生します。 RTF パーサーが atoi または atol を呼び出して、数値文字列を整数に変換していると思われるかもしれません。しかし、そうではありません。 Microsoft Word の RTF パーサーは、これらの標準 C ランタイム関数を使用しません。代わりに、Microsoft Word の RTF パーサーの atoi 関数は次のように実装されています。

b. ucN および uN
どちらも無視され、uN の直後の文字はスキップされません。
c.空白文字: 0x0D (n)、0x0A (r)、0x09 (t) は無視されます。
d.エスケープ文字
RTF には、予約されている特殊な記号がいくつかあります。通常の使用では、ユーザーはこれらの記号をエスケープする必要があります。以下は不完全なリストです。
}
{
%
+
–
‘hh
これらのエスケープ文字はすべて無視されますが、’hh. には興味深い状況があります。最初に例を見てみましょう。
|
難読化 |
{objectobjocxobjdata 341’112345} |
|
クリア |
{objectobjocxobjdata 342345} |
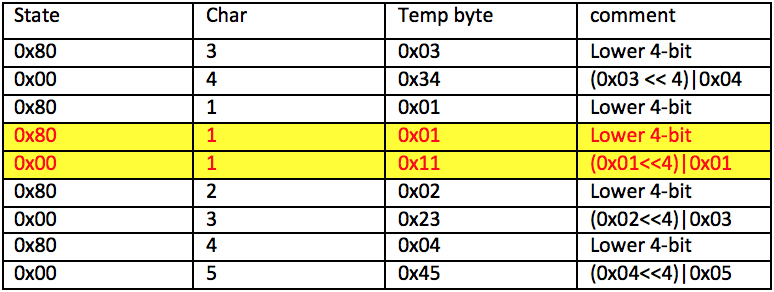
’11 を解析するとき、パーサーは 11 をエンコードされた 16 進バイトとして扱います。この 16 進バイトは、objdata の残りの解析を続行する前に破棄されます。 1 つ前の ’11 も破棄されています。 RTF パーサーが、オクテットの上位 4 ビットである ’11 の直前の 1 を解析し、すぐに ’11 に遭遇すると、上位 4 ビットは破棄されます。これは、16 進文字列を 2 進バイトにデコードするための内部状態がリセットされたためです。
下の表は処理手順を表したもので、黄色の行の 2 つの 1 は ’11 からのものです。 ’11 が混在していると状態変数が乱れ、2 番目のバイトの上位 4 ビットが破棄されることは明らかです。
e.大きすぎるコントロール ワードと数値パラメータ
RTF 仕様では、コントロール ワードの名前は 32 文字を超えることはできず、コントロール ワードに関連付けられた数値パラメーターは符号付き 16 ビット整数または符号付き 32 ビット整数でなければならないと規定されていますが、Microsoft Office の RTF パーサーは厳密にはそうではありません。仕様に従います。その実装では、制御語文字列と数値パラメータ文字列を格納するために、サイズ 0xFF のバッファのみが予約されます。これらは両方とも null で終了します。最大バッファー長 (0xFF) の後のすべての文字は、コントロール ワードまたはパラメーター文字列の一部として残りません。代わりに、コントロール ワードまたはパラメーターが終了します。
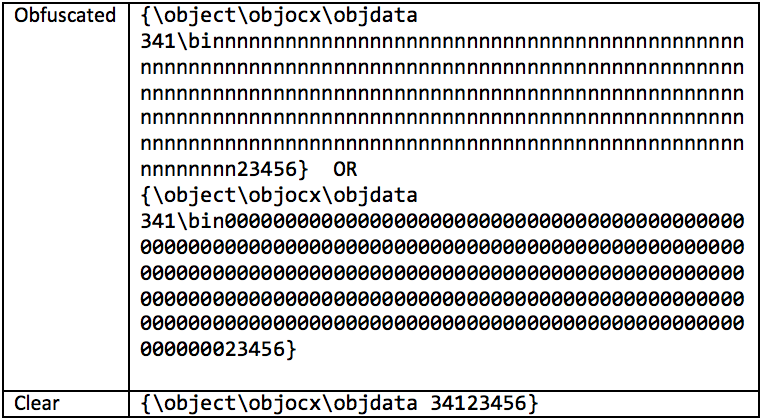
最初の難読化された例では、大きすぎるコントロール ワードの長さは 0xFE です。 null ターミネータを追加すると、コントロール ワード文字列は最大長の 0xFF に達し、残りのデータは objdata に属します。
難読化された 2 番目の例では、「bin」コントロール ワードとそのパラメータの合計の長さは 0xFD です。 null ターミネータを追加すると、長さは 0xFF になります。
f.追加のテクニック
次に示すように、プログラムはリストの最後の objdata コントロール ワードを使用します。
|
難読化 |
{objectobjocxobjdata 554564{*objdata 4444}54545} または {objectobjocxobjdata 554445objdata 444454545} {objectobjocx{{objdata 554445}{objdata 444454545}}} |
|
クリア |
{objectobjocxobjdata 444454545} |
ここでわかるように、binN を除いて、他の制御語は無視されます。
|
難読化 |
{objectobjocxobjdata 44444444{par2211 5555}6666} または {objectobjocxobjdata 44444444{datastore2211 5555}6666} または {objectobjocxobjdata 44444444datastore2211 55556666} または {objectobjocxobjdata 44444444{unknown2211 5555}6666} または {objectobjocxobjdata 44444444unknown2211 55556666} |
|
クリア |
{objectobjocxobjdata 4444444455556666} |
状況をもう少し複雑にする特殊なケースがもう 1 つあります。それが制御記号 * です。 RTF 仕様から、この制御記号の説明を取得できます。
1987 RTF 仕様以降に追加された宛先には、制御記号* (バックスラッシュ アスタリスク) を前に付けることができます。この制御記号は、RTF リーダーが宛先制御語を認識しない場合に関連テキストを無視する宛先を識別します。
難読化でどのように使用できるかを見てみましょう。
1.
|
難読化 |
{objectobjocxobjdata 44444444{*par314 5555}6666} |
|
クリア |
{objectobjocxobjdata 4444444455556666} |
par は、データを受け入れない既知の制御語です。 RTF パーサーはコントロール ワードをスキップし、後続のデータのみが残ります。
2.
|
難読化 |
{objectobjocxobjdata 44444444{*datastore314 5555}6666} |
|
クリア |
{objectobjocxobjdata 444444446666} |
RTF パーサーも datastore を認識し、データを受け入れることができることを理解できるため、次のデータは datastore によって消費されます。
3.
|
難読化 |
{objectobjocxobjdata 44444444{*unknown314 5555}6666} |
|
クリア |
{objectobjocxobjdata 444444446666} |
アナリストにとって、難読化された RTF から埋め込みオブジェクトを手動で抽出することは困難であり、難読化された RTF を処理できる公開ツールはありません。ただし、winword.exe は OleConvertOLESTREAMToIStorage 関数を使用して、OLE1 ネイティブ データを OLE2 構造化ストレージ オブジェクトに変換します。 OleConvertOLESTREAMToIStorage のプロトタイプを次に示します。

lpolestream が指すオブジェクトには、OLE1 ネイティブ バイナリ データへのポインターが含まれています。 OleConvertOLESTREAMToIStorage にブレークポイントを設定し、RTF パーサーによって難読化が解除されたオブジェクト データをダンプできます。
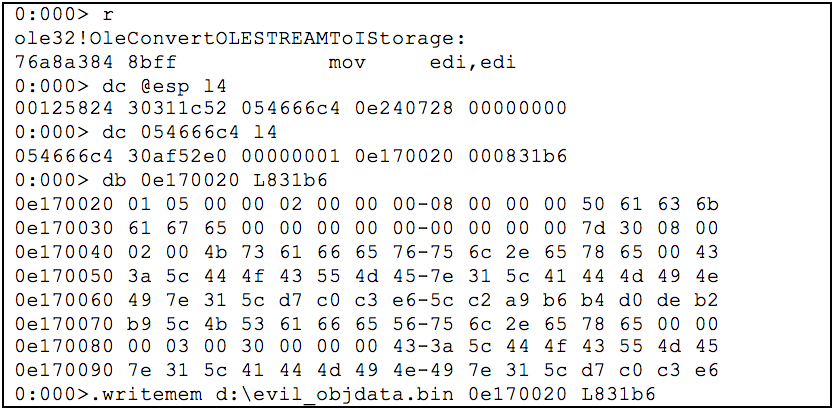
最後のコマンド .writemem は、メモリのセクションを d:evil_objdata.bin に書き込みます。必要に応じて他のパスを指定できます。 0e170020 はメモリ範囲の開始アドレスで、831b6 はサイズです。
objdata の難読化手法のほとんどは埋め込み画像にも適用できますが、画像の場合、OleConvertOLESTREAMToIStorage のような明白な手法はないようです。難読化された画像を抽出するには、データ ブレークポイントを使用して RTF 解析コードをすばやく見つけます。これにより、データ全体をダンプするのに最適なポイントが明らかになります。
結論
私たちの攻撃者は洗練されており、RTF 形式と Microsoft Word の内部動作に精通しています。彼らは、これらの難読化のトリックを考案して、従来のシグネチャベースの検出を回避することに成功しました.敵対者がどのように難読化を行っているかを理解することは、そのようなマルウェアの検出を改善するのに役立ちます。
謝辞
このブログに貢献してくれた Yinhong Chang、Jonell Baltazar、Daniel Regalado に感謝します。
参照: https://www.mandiant.com/resources/blog/how-rtf-malware-evad


Comments