FireEye では、攻撃者を検出、追跡、阻止するために懸命に取り組んでいます。この作業の一環として、一般的に使用されるマルウェア、インフラストラクチャ、配信メカニズム、その他のツールや手法に関する詳細を含め、さまざまな攻撃者がどのように動作するかについて多くの情報を学びます。この知識は、毎年何百回もの調査と何千時間もの分析によって蓄積されています。本書の発行時点では、50 の APT または FIN グループがあり、それぞれが異なる特徴を持っています。また、正式な帰属の主張をまだ行っていない、特徴付けられていない関連アクティビティの数千の「クラスター」も収集しました。属性はありませんが、これらのクラスターは、関連付けられたアクティビティをグループ化して経時的に追跡できるという意味で、依然として有用です。
しかし、収集する情報がますます大きくなるにつれて、この情報を大規模に分析し、新しい潜在的な重複や属性を発見するのに役立つアルゴリズム手法が必要であることに気付きました。このブログ投稿では、モデルの構築に使用したデータ、開発したアルゴリズム、および今後取り組んでいきたいいくつかの課題について概説します。
データ
悪意のあるアクティビティを検出して明らかにすると、フォレンジックに関連するアーティファクトが「クラスター」にグループ化されます。これらのクラスターは、アクション、インフラストラクチャ、およびマルウェアのすべてが、直接リンクする侵入、キャンペーン、または一連のアクティビティの一部であることを示しています。これらは、「UNC」または「未分類」グループと呼ばれるものです。時間の経過とともに、これらのクラスターは成長し、他のクラスターとマージされ、APT33 や FIN7 などの名前付きグループに「卒業」する可能性があります。攻撃ライフサイクルの各フェーズにおける攻撃者の活動について十分に理解し、その活動を国家主導のプログラムまたは犯罪活動と関連付けた場合にのみ、この段階化が行われます。
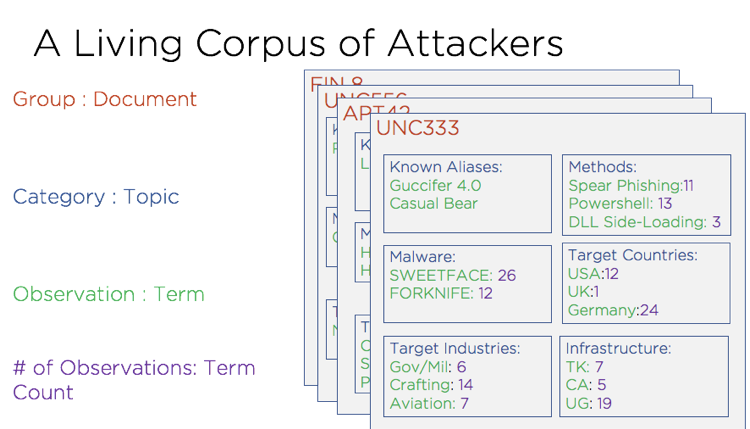
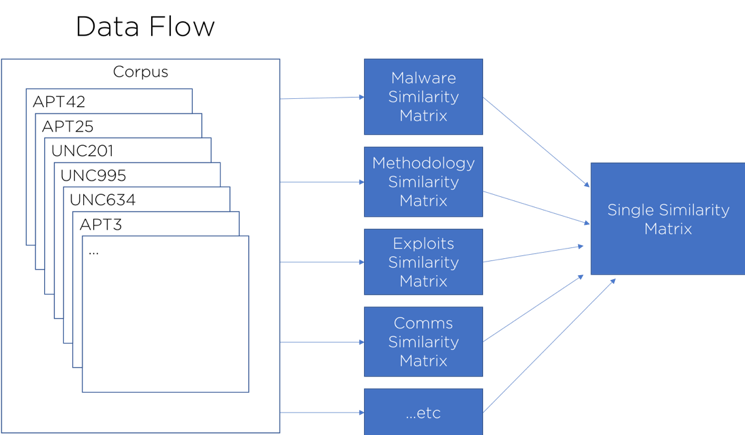
すべてのグループについて、インフラストラクチャ、マルウェア ファイル、通信方法、その他の側面などのセクションに分割された情報を含む概要ドキュメントを生成できます。図 1 は、さまざまな「トピック」が分割された、製造された例を示しています。 「マルウェア」などの各「トピック」内には、カウントが関連付けられたさまざまな「用語」があります。これらの数値は、その「用語」を使用してグループを記録した頻度を示しています。

問題
私たちの最終目標は常に、リンクが証明されたら新しいグループを既存のグループにマージするか、それが新しくて異なるアクター セットを表していると確信している場合は、それを独自のグループに卒業させることです。これらのクラスタリングと属性の決定は、これまで手作業で行われており、厳密な分析と正当化が必要です。しかし、攻撃者の活動に関するデータがますます多く収集されるにつれて、この手作業による分析がボトルネックになります。クラスターは分析されないままになるリスクがあり、潜在的な関連性や属性が見過ごされる可能性があります。したがって、これらの主張の発見、分析、および正当化を支援するために、機械学習ベースのモデルをインテリジェンス分析に組み込むようになりました。
私たちが開発したモデルは、次の目標から始まりました。
- グループ間で単一の解釈可能な類似性指標を作成する
- 過去の分析決定を評価する
- 新しい潜在的な一致を発見する

モデル
このモデルは、データ サイエンスの分野でよく知られているドキュメント クラスタリング アプローチを使用しており、書籍や映画のグループ化のコンテキストで説明されることがよくあります。各グループに関する構造化ドキュメントにアプローチを適用すると、グループ間の類似性を大規模に評価できます。
まず、各トピックを個別にモデル化することにしました。この決定は、各トピックがグループ間の類似性の独自の測定値をもたらし、最終的に集約されて全体的な類似性測定値を生成することを意味します。
これをドキュメントに適用する方法を次に示します。
各トピック内で、用語頻度 – 逆ドキュメント頻度 ( TF-IDF ) と呼ばれる方法を使用して、すべての個別の用語が値に変換されます。この変換は、すべてのドキュメントとトピックのすべての固有の用語に適用されます。その背後にある基本的な直感は次のとおりです。
- ドキュメントで頻繁に使用される場合は、用語の重要性を高めます。
- 用語がすべての文書に共通して現れる場合は、その用語の重要度を下げます。
このアプローチでは、カスタム マルウェア ファミリなどの特徴的な用語 (少数のグループにのみ出現する可能性があります) が重視され、大多数のグループに出現する「スピア フィッシング」などの一般的な用語が軽視されます。
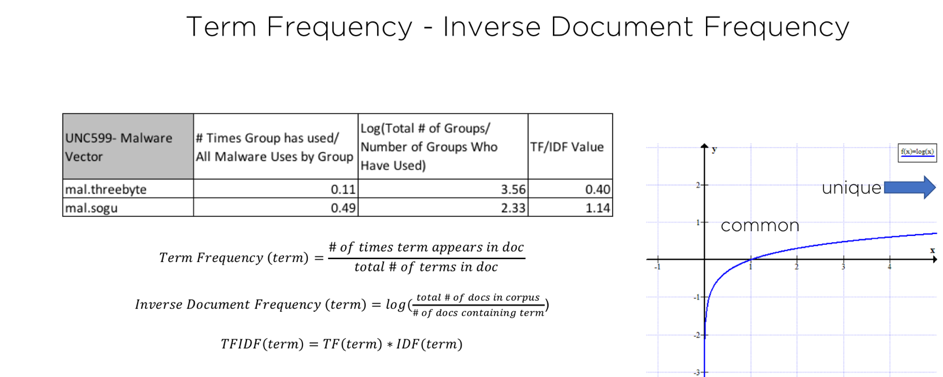
図 3 は、 mal.soguとmal.threebyteという 2 つの用語について、架空の「UNC599」に TF-IDF を適用した例を示しています。これらの用語は、「マルウェア」トピック内での SOGU と THREEBYTE の使用法を示しているため、TF-IDF を使用してそのトピック内での値を計算します。最初の (TF) 値は、それらの用語がグループのすべてのマルウェア用語の一部として出現した頻度です。 2 番目の値 (IDF) は、これらの用語がすべてのグループで出現する頻度の逆数です。さらに、非常に一般的な項の影響を平滑化するために、IDF 値の自然対数を取ります。グラフでわかるように、値が 1 に近い場合 (非常に一般的な項)、対数はゼロに近いと評価されます。したがって、最終的な TF x IDF 値の重みを下げます。一意の値は IDF がはるかに高いため、値が高くなります。
各用語にスコアが与えられると、各グループは個別のトピックのコレクションとして反映され、各トピックは含まれる用語のスコアのベクトルになります。各ベクトルは、グループがそのトピック内で「指している」「方向」を詳述する矢印として考えることができます。
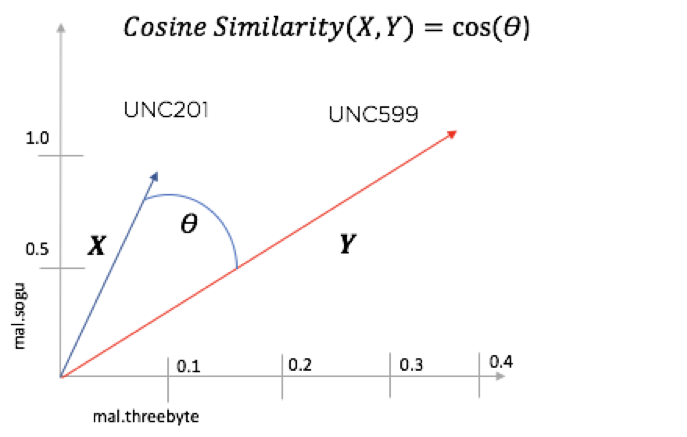
各トピック空間内で、別の方法であるコサイン類似度を使用して、さまざまなグループの類似性を評価できます。私のように、三角法が好きでなかったとしても、恐れる必要はありません。直感は単純です。本質的に、これは 2 つのベクトルがどの程度平行であるかの尺度です。図 4 に示すように、2 つのグループのマルウェアの使用状況を評価するために、それらのマルウェア ベクトルをプロットし、それらが同じ方向を向いているかどうかを確認します。より類似しているということは、それらがより類似していることを意味します。
このアプローチの優れた点の 1 つは、大きなベクトルと小さなベクトルが同じように扱われることです。したがって、十分に文書化された APT グループと同じ方向を指している新しい比較的小さな UNC クラスターでも、高いレベルの類似性が反映されます。これは私たちが持っている主な使用例の 1 つであり、すでに確立されているグループと高い類似性を持つアクティビティの新しいクラスターを発見します。
TF-IDF と Cosine Similarity を使用して、ドキュメントのコーパス内のすべてのグループのトピック固有の類似度を計算できるようになりました。最後のステップは、これらのトピックの類似性を 1 つの集計メトリックに結合することです (図 5)。この単一のメトリックにより、「X に類似したグループ」または「X と Y の間の類似性」についてデータをすばやくクエリできます。質問は次のようになります: この最終的な類似性を構築するための最良の方法は何ですか?
最も単純なアプローチは平均を取ることであり、最初はまさにそれを実行しました。ただし、アナリストとして、このアプローチはアナリストの直感とうまく一致しませんでした。アナリストとして、一部のトピックは他のトピックよりも重要であると感じています。マルウェアと方法論は、サーバーの場所や対象となる業界などよりも重要です。しかし、トピックごとにカスタムの重み付けを提供しようとすると、アナリストの偏見のない客観的な重み付けシステムを見つけることができませんでした。最後に、「既存の既知のデータを使用して適切な重みを教えてはどうでしょうか?」と考えました。そのためには、類似グループと非類似グループの両方の既知の、または「ラベル付けされた」多くの例が必要でした。
ラベル付きデータセットの構築
最初は、私たちのコンセプトは単純に見えました。ラベル付きペアの大規模なデータセットを見つけて、回帰モデルを適合させてそれらを正確に分類するというものでした。成功した場合、このモデルは、発見したい重みを与えるはずです。
図 6 は、このアプローチの背後にあるグラフィカルな直感を示しています。まず、「ラベル付けされた」ペアのセットを使用して、データ ポイントを最適に予測する関数を当てはめます。
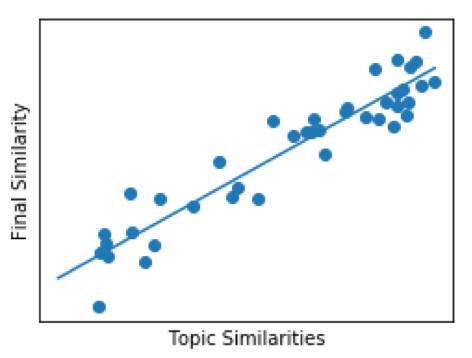
次に、同じ関数を使用して、ラベル付けされていないペアの総類似度を予測します (図 7)。
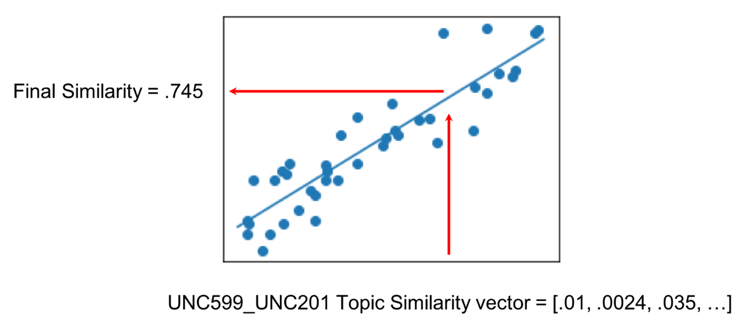
しかし、私たちのデータは、すべての潜在的なペアリングのほんの一部しか分析されていないという意味で、独特の問題を提起しました.これらの分析は手動で散発的に行われ、多くの場合、調査からの突然の新しい情報が最終的に 2 つのグループを結び付けた結果です。ラベル付けされたデータセットとして、これらのペアはアプローチの厳密な評価にはひどく不十分でした.より多くのラベル付きデータが必要でした。
2 人のデータ サイエンティストが巧妙なアプローチを提案しました。定評のある APT グループからランダムにサンプリングして、何千もの「偽の」クラスターを作成したらどうなるでしょうか?したがって、同じグループからの 2 つのサンプルは確実に類似しているとラベル付けし、別のグループからの 2 つのサンプルは類似していないとラベル付けできます (図 8)。これにより、どうしても必要だったラベル付きデータセットを合成的に生成することができました。次に、線形回帰モデルを使用して、主観的な推測に頼るのではなく、この「加重平均」の問題をエレガントに解決することができました。

さらに、これらの人工的に作成されたクラスターは、モデルのさまざまな反復をテストするためのデータセットを提供してくれました。トピックを削除するとどうなりますか?用語を捉える方法を変えたらどうなるでしょうか?ラベル付けされた大規模なデータセットを使用して、モデルを更新および改善しながらパフォーマンスをベンチマークおよび評価できるようになりました。
モデルを評価するために、いくつかの指標を観察します。
- 同じ元のグループから来ていることがわかっている合成クラスターを思い出してください。いくつが正しい/間違っているでしょうか?これは、与えられたアプローチの精度を評価します。
- 個々のトピックについて、関連クラスターと非関連クラスターの計算された類似度間の「広がり」。これは、どのトピックがクラスの分離に最も役立つかを特定するのに役立ちます。
- トピックで表される、類似クラスターと非類似クラスター間の「シグナル」のプロキシとしての、トレーニング済み回帰モデルの精度。これは、オーバーフィッティングの問題を特定するのにも役立ちます。
運用上の使用
私たちの日常業務において、このモデルはインテリジェンスの専門家を補強し、支援するのに役立ちます。客観的な類似点を提示することで、偏見に挑戦し、以前は考慮されていなかった新しい調査ラインを導入できます。世界中のアナリストから毎日追加される数千のクラスターと新しいクラスターを処理する場合、最も経験豊富で意識の高いインテル アナリストでさえ、潜在的なリードを見逃す可能性があります。ただし、私たちのモデルは、可能性のあるマージと類似点をオンデマンドでアナリストに提示できるため、アナリストの発見を支援できます。
これを 2018 年 12 月にシステムに導入したところ、すぐにメリットが見つかりました。一例は、潜在的に破壊的な攻撃に関するこのブログ投稿で概説されています。それ以来、私たちは何十もの他のマージについて通知、発見、または正当化することができました。
今後の課題
すべてのモデルと同様に、これには弱点があり、すでに改善に取り組んでいます。調査からの情報を手動で入力する方法には、ラベル ノイズがあります。私たちのドキュメントには (まだ) 記載されていない、攻撃者に関する「余分な」データが存在する場合があります。何よりも、まだ「活動時間」を完全に組み込んでおらず、代わりに「記録時間」に依存しています。これにより、表現に遅れが生じ、時間ベースの分析が困難になります。攻撃者が最近行ったことは、5 年前に行ったことよりも意味があるはずです。
この客観的なアプローチを採用してモデルを構築することで、インテルの運用が改善されただけでなく、将来のモデリング作業に必要なデータが明らかになりました。他の分野で見てきたように、フォレンジック データに基づいて機械学習モデルを構築すると、データ モデリング、ストレージ、およびアクセスの改善の可能性がすぐに明らかになります。このモデルの詳細については、2018 CAMLISカンファレンスでのプレゼンテーションからのこのビデオでもご覧いただけます。
これまでのところ、私たちはインテリジェンス モデルを拡張するためにこのアプローチを採用することを楽しんでおり、今後の潜在的な道に興奮しています。何よりも、攻撃者のプロファイリング、属性の特定、阻止に役立つモデリングの取り組みを楽しみにしています。
参照: https://www.mandiant.com/resources/blog/clustering-and-associating-attacker-activity-at-scale


Comments