
目標を達成するのに役立つツールや技術を採用することに何の制約も示さない攻撃者の一歩先を行くために、Microsoft は AI と機械学習を利用してセキュリティの課題を解決し続けています。私たちが実験してきた分野の 1 つは、自律システムです。シミュレートされたエンタープライズ ネットワークでは、特定の知識やパラメーターを使用して一連の操作を独立して実行するインテリジェント システムである自律エージェントが環境内でどのように相互作用するかを調べ、強化学習手法を適用してセキュリティを向上させる方法を研究します。
今日は、これらの実験の結果を共有したいと思います。私たちは、CyberBattleSim と呼ばれる研究ツールキットの Python ソース コードをオープン ソース化しています。これは、コンピュータ ネットワークの高度な抽象化とサイバーセキュリティの概念を使用して、シミュレートされたエンタープライズ環境で自律型エージェントがどのように動作するかを調査する実験的研究プロジェクトです。このツールキットは、Python ベースの OpenAI Gym インターフェイスを使用して、強化学習アルゴリズムを使用した自動エージェントのトレーニングを可能にします。コードはこちらから入手できます: https://github.com/microsoft/CyberBattleSim
CyberBattleSim は、コンピューター システムの複雑さの非常に抽象的なシミュレーションを構築する方法を提供し、強化学習のコンテキストでサイバーセキュリティの課題を組み立てることを可能にします。この研究ツールキットを広く共有することで、私たちはコミュニティが私たちの研究に基づいて構築し、サイバーエージェントがシミュレートされた環境でどのように相互作用して進化するかを調査し、サイバーセキュリティの概念の高レベルの抽象化がサイバーエージェントがどのように行動するかを理解するのにどのように役立つかを研究することを奨励します実際の企業ネットワーク。
この調査は、機械学習と AI を活用してセキュリティを継続的に改善し、防御側の作業を自動化するためのマイクロソフト全体の取り組みの一環です。マイクロソフトが委託した最近の調査によると、組織のほぼ 4 分の 3 が、チームが自動化すべきタスクに多くの時間を費やしていると述べています。このツールキットが、自律システムと強化学習を利用して回復力のある実世界の脅威検出技術と堅牢なサイバー防御戦略を構築する方法を探求するためのより多くの研究を刺激することを願っています。
セキュリティへの強化学習の適用
強化学習は、自律エージェントが環境と対話することによって意思決定を行う方法を学習する機械学習の一種です。エージェントは環境と対話するためにアクションを実行する場合があり、その目標は報酬の概念を最適化することです。人気があり成功しているアプリケーションの 1 つは、環境がすぐに利用できるビデオ ゲームに見られます。それは、ゲームを実装するコンピューター プログラムです。ゲームのプレーヤーはエージェントであり、実行するコマンドはアクションであり、最終的な報酬はゲームに勝つことです。最高の強化学習アルゴリズムは、環境の各状態でどのようなアクションを実行するかを徐々に学習することで、経験を重ねることで効果的な戦略を学習できます。エージェントはゲームをプレイすればするほど、より賢くゲームに取り掛かります。強化学習の分野における最近の進歩により、ビデオゲームをプレイする際に人間のレベルを超える自律エージェントをうまくトレーニングできることが示されました。
昨年、私たちは強化学習のソフトウェア セキュリティへの応用の調査を開始しました。これを行うために、強化学習のコンテキストでソフトウェアのセキュリティの問題を考えました。攻撃者または防御者は、コンピューター ネットワークによって提供される環境で進化するエージェントと見なすことができます。それらのアクションは、利用可能なネットワークおよびコンピューター コマンドです。通常、攻撃者の目的は、ネットワークから機密情報を盗むことです。防御側の目標は、攻撃者を排除するか、他の種類の操作を実行してシステムに対する攻撃を軽減することです。

図 1. 強化学習の概念をセキュリティにマッピングする
このプロジェクトでは、 OpenAI Gymを使用しました。これは、強化学習の研究者が自律型エージェントをトレーニングするための新しいアルゴリズムを開発、トレーニング、および評価するためのインタラクティブな環境を提供する一般的なツールキットです。このツールキットを使用して構築された環境の注目すべき例には、ビデオ ゲーム、ロボット シミュレータ、および制御システムが含まれます。
もちろん、コンピューターとネットワーク システムは、ビデオ ゲームよりもはるかに複雑です。通常、ビデオ ゲームでは一度に許可されるアクションは少数ですが、コンピューターやネットワーク システムとやり取りする場合は、膨大な数のアクションを使用できます。たとえば、ネットワーク システムの状態は巨大であり、ボード ゲームの有限の位置リストとは対照的に、容易かつ確実に取得することはできません。しかし、これらの課題があっても、OpenAI Gym は私たちの研究に適したフレームワークを提供し、CyberBattleSim の開発につながりました。
CyberBattleSim の仕組み
CyberBattleSim は、サイバー攻撃の侵害後の水平移動段階をモデル化する脅威に焦点を当てています。この環境は、コンピューター ノードのネットワークで構成されています。これは、固定ネットワーク トポロジと、エージェントがネットワークを横方向に移動するために悪用できる一連の事前定義された脆弱性によってパラメータ化されます。シミュレートされた攻撃者の目標は、これらの植え付けられた脆弱性を悪用して、ネットワークの一部の所有権を取得することです。シミュレートされた攻撃者がネットワークを移動している間、防御エージェントはネットワーク アクティビティを監視して、攻撃者の存在を検出し、攻撃を封じ込めます。
以下のグラフは、さまざまなオペレーティング システムとソフトウェアを実行しているマシンを含むネットワークのおもちゃの例を示しています。各マシンには、一連のプロパティ、値、および事前に割り当てられた脆弱性があります。黒いエッジは、ノード間で実行されるトラフィックを表し、通信プロトコルによってラベル付けされています。
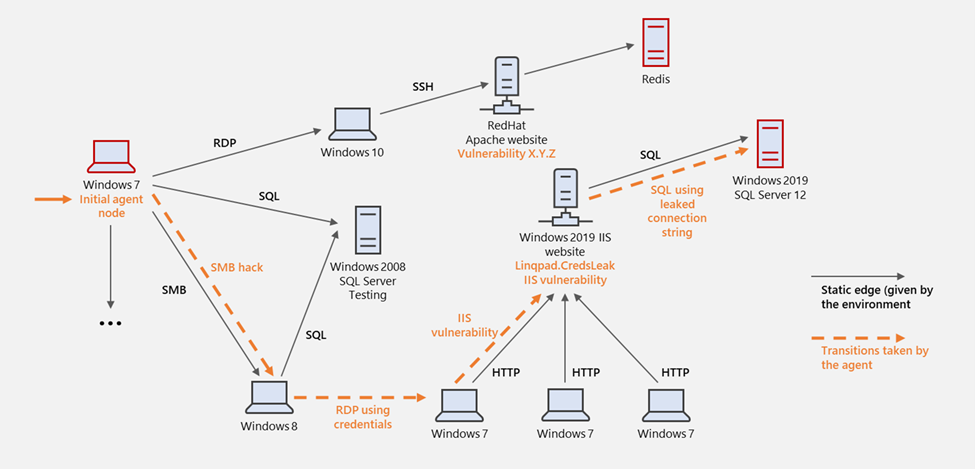
図 2. コンピュータ ネットワーク シミュレーションにおけるラテラル ムーブメントの視覚的表現
エージェントが攻撃者を表すとします。侵害後の仮定は、最初に 1 つのノードが攻撃者のコードに感染したことを意味します (攻撃者がノードを所有していると言えます)。シミュレートされた攻撃者の目標は、ネットワーク内のノードを発見して所有権を取得することにより、累積報酬を最大化することです。環境は部分的に観察可能です。エージェントは、ネットワーク グラフのすべてのノードとエッジを事前に確認することはできません。代わりに、攻撃者は、現在所有しているノードからネットワークを徐々に探索するためのアクションを実行します。アクションには、ローカル攻撃の実行、リモート攻撃の実行、および他のノードへの接続という3 種類のアクションがあり、エクスプロイト機能と探索機能の組み合わせをエージェントに提供します。アクションは、基になる操作が行われるソース ノードによってパラメーター化され、エージェントが所有するノードでのみ許可されます。報酬は、ノードの本質的な価値を表す float です (たとえば、SQL サーバーはテスト マシンよりも価値があります)。
図示の例では、シミュレートされた攻撃者が、シミュレートされた Windows 7 ノード (左側、オレンジ色の矢印で示されている) からネットワークに侵入しています。 SMB ファイル共有プロトコルの脆弱性を悪用して Windows 8 ノードへの水平移動を進め、キャッシュされた認証情報を使用して別の Windows 7 マシンにサインインします。次に、IIS リモートの脆弱性を悪用して IIS サーバーを所有し、最終的に漏洩した接続文字列を使用して SQL DB にアクセスします。
この環境は、複数のプラットフォームをサポートする異種コンピューター ネットワークをシミュレートし、最新のオペレーティング システムを使用してこれらのシステムを最新の状態に保つことで、組織が Windows 10 などのプラットフォームで最新の強化および保護テクノロジを利用できるようにする方法を示すのに役立ちます。シミュレーション ジム環境は、ネットワーク レイアウトの定義、サポートされている脆弱性のリスト、および脆弱性が植え付けられているノードによってパラメータ化されます。シミュレーションはマシン コードの実行をサポートしていないため、セキュリティの悪用は実際には行われません。代わりに、以下を定義する前提条件で脆弱性を抽象的にモデル化します: 脆弱性がアクティブなノード、悪用が成功する確率、および結果と副作用の高レベルの定義。ノードには、事前条件がブール式として表現される名前付きプロパティが事前に割り当てられています。
脆弱性の結果
資格情報の漏えい、他のコンピュータ ノードへの参照の漏えい、ノード プロパティの漏えい、ノードの所有権の取得、ノードでの特権エスカレーションなどの定義済みの結果があります。リモートの脆弱性の例としては、 ssh資格情報を公開している SharePoint サイト、マシンへのアクセスを許可するsshの脆弱性、コミット履歴で資格情報を漏えいする GitHub プロジェクト、ストレージ アカウントへの SAS トークンを含むファイルを含む SharePoint サイトなどがあります。一方、ローカルの脆弱性の例としては、システム キャッシュからの認証トークンまたはクレデンシャルの抽出、SYSTEM 権限への昇格、管理者権限への昇格などがあります。脆弱性は、ノード レベルでインプレースで定義することも、グローバルに定義して前提条件のブール式でアクティブ化することもできます。
ベンチマーク: 進捗状況の測定
事前定義された成功確率に基づいて進行中の攻撃を検出して軽減する、基本的な確率論的ディフェンダーを提供します。感染したノードを再イメージ化することで軽減策を実装します。これは、複数のシミュレーション ステップにまたがる操作として抽象的にモデル化されたプロセスです。エージェントのパフォーマンスを比較するために、2 つのメトリクスを調べます。目標を達成するために実行されたシミュレーション ステップの数と、トレーニング エポック全体のシミュレーション ステップに対する累積報酬です。
セキュリティ問題のモデル化
ジム環境のパラメーター化可能な性質により、さまざまなセキュリティ問題のモデル化が可能になります。たとえば、以下のコード スニペットは、攻撃者の目標がネットワーク内の貴重なノードとリソースの所有権を取得することであるキャプチャー ザ フラグチャレンジに着想を得ています。

図 3.シミュレーション環境のインスタンスを記述するコード
この例では、攻撃者をインタラクティブにプレイするための Jupyter ノートブックを提供します。
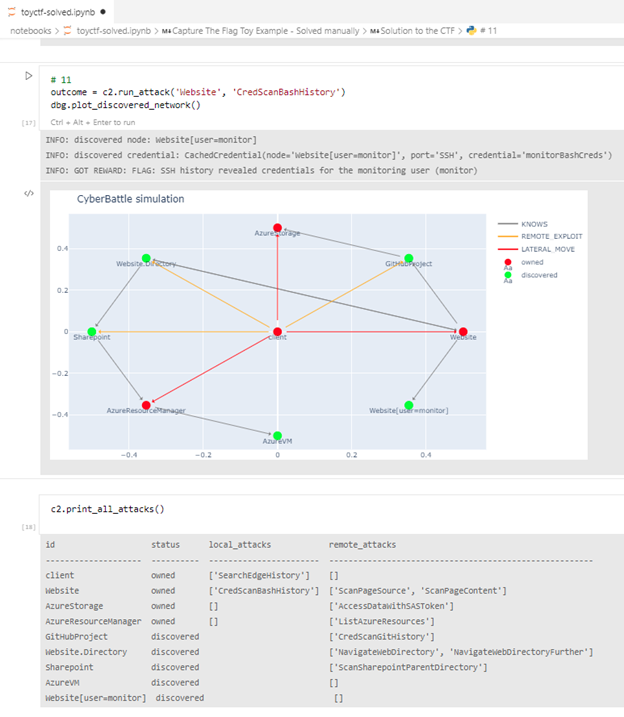
図 4. シミュレーションをインタラクティブに再生する
Gym インターフェイスを使用すると、自動化されたエージェントを簡単にインスタンス化し、そのような環境でエージェントがどのように進化するかを観察できます。以下のスクリーンショットは、このシミュレーションでランダム エージェントを実行した結果を示しています。つまり、シミュレーションの各ステップで実行するアクションをランダムに選択するエージェントです。
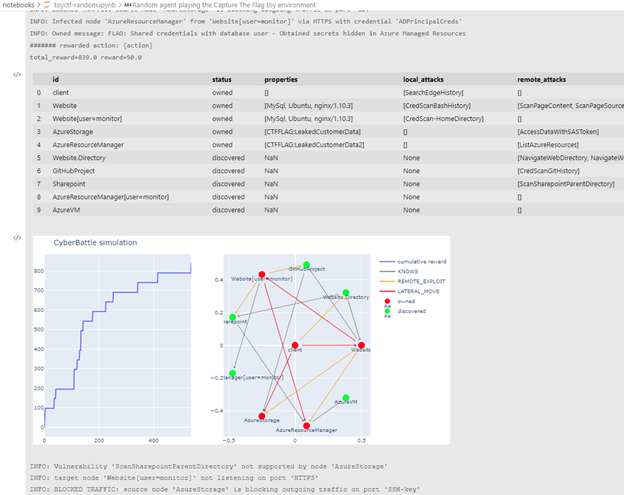
図 5. シミュレーションと対話するランダム エージェント
Jupyter ノートブックの上記のプロットは、シミュレーション エポック (左) と探索されたネットワーク グラフ (右) に沿って累積報酬関数がどのように成長するかを示しており、感染したノードは赤でマークされています。この実行では、この状態に到達するまでに約 500 のエージェント ステップが必要でした。ログは、試行されたアクションの多くが失敗したことを示しています。一部はファイアウォール ルールによってトラフィックがブロックされたことが原因で、一部は不適切な資格情報が使用されたためです。現実の世界では、このような不規則な動作はすぐにアラームをトリガーし、Microsoft 365 Defender のような防御 XDR システムや Azure Sentinel のような SIEM/SOAR システムが迅速に対応し、悪意のあるアクターを追い出します。
このようなおもちゃの例では、ネットワークの完全な所有権を取得するために約 20 のアクションしか実行しない攻撃者にとって最適な戦略が可能になります。人間のプレイヤーが最初の試行でこのゲームに勝つには、平均で約 50 回の操作が必要です。ネットワークは静的であるため、繰り返し再生した後、人間はやりがいのあるアクションの正しいシーケンスを覚えており、最適なソリューションをすばやく決定できます。
ベンチマークの目的で、さまざまなサイズの単純なおもちゃの環境を作成し、さまざまな強化アルゴリズムを試しました。次のプロットは結果をまとめたものです。Y 軸は、複数回繰り返されるエピソード (X 軸) でネットワークの完全な所有権を取得するために実行されたアクションの数 (低いほど良い) です。 Q ラーニングなどの特定のアルゴリズムが徐々に改善され、人間のレベルに到達する方法に注意してください。他のアルゴリズムは 50 エピソード後もまだ苦労しています!

図 6. さまざまな強化学習アルゴリズムでトレーニングされたエージェントのエポックに沿った反復回数
累積報酬プロットは、エージェントがノードに感染するたびに報酬を得る別の比較方法を提供します。暗い線は中央値を示し、影は 1 つの標準偏差を表します。これは、特定のエージェント (赤、青、および緑) が他のエージェント (オレンジ) よりも明らかに優れていることを示しています。
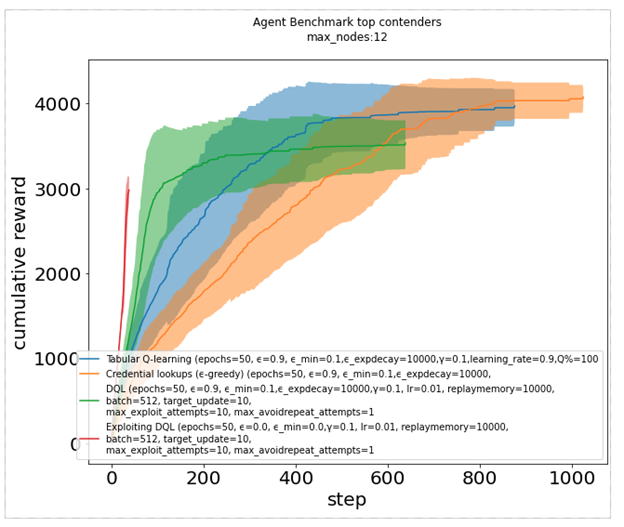
図 7. さまざまな強化学習アルゴリズムの累積報酬プロット
一般化
学習した戦略が他の環境でうまく機能しない場合、固定された環境でうまく実行する方法を学習しても、それほど役に立ちません。戦略をうまく一般化する必要があります。部分的に観測可能な環境を持つことで、ネットワークの一部のグローバルな側面や次元への過剰適合を防ぐことができます。ただし、エージェントが、順番に実行するアクションの固定シーケンスを記憶するなど、一般化できない戦略を学習することを妨げるものではありません。これをよりよく評価するために、さまざまなサイズの環境のセットを検討しましたが、ネットワーク構造は共通です。特定のサイズの 1 つの環境でエージェントをトレーニングし、より大きな環境または小さな環境で評価します。これにより、同じ構造を維持しながら動的に拡大または縮小する環境でエージェントがどのように機能するかについてのアイデアも得られます。
うまく機能させるために、エージェントは対話しているインスタンスに固有ではない観察から学習する必要があります。ノード インデックスやネットワーク サイズに関連するその他の値だけを覚えているわけではありません。代わりに、一時的な特徴や機械の特性を観察できます。たとえば、マシン上に存在するソフトウェアに基づいて、実行する最適な操作を選択できます。以下の 2 つの累積報酬プロットは、以前にサイズ 4 のインスタンスでトレーニングされた 1 つのエージェントが、サイズ 10 のより大きなインスタンス (左) と相互に (右) でどのように非常にうまく機能するかを示しています。
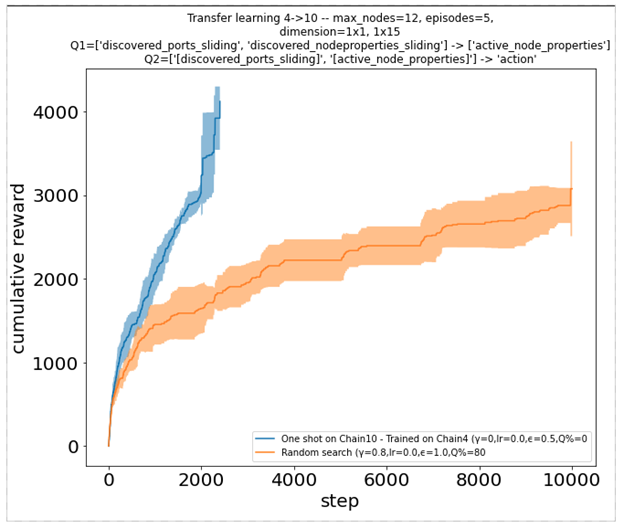
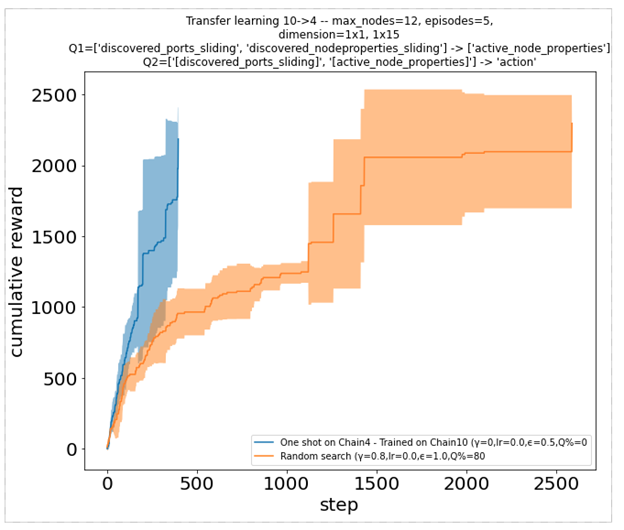
図 8. 異なる環境で事前トレーニングされたエージェントの累積報酬関数
強化学習のセキュリティへの応用を探求し続けるための招待状
コンピューター システムの複雑さの一部を抽象化すると、強化学習の問題のインスタンスとしてサイバーセキュリティの問題を定式化することができます。 OpenAI ツールキットを使用すると、複雑なコンピューター システムの非常に抽象的なシミュレーションを構築し、最先端の強化アルゴリズムを簡単に評価して、自律エージェントがどのように相互作用し、それらから学習するかを研究できます。
改善の潜在的な領域は、シミュレーションのリアリズムです。 CyberBattleSim のシミュレーションは単純化されており、利点があります。その高度に抽象化された性質により、現実世界のシステムへの直接的な適用が禁止されているため、それで訓練された自動化されたエージェントの潜在的な悪用に対する保護が提供されます。また、私たちが研究しようとしているセキュリティの特定の側面に焦点を当て、最近の機械学習と AI アルゴリズムをすばやく実験することもできます。現在、ネットワーク トポロジと構成がこれらの技術にどのように影響するかを理解することを目標に、ラテラル ムーブメント技術に焦点を当てています。このような目標を念頭に置いて、実際のネットワーク トラフィックをモデル化する必要はないと感じましたが、これらは将来の貢献で対処できる重大な制限です。
アルゴリズムの面では、現在、比較のためのベースラインとしていくつかの基本的なエージェントのみを提供しています。最先端の強化学習アルゴリズムがそれらとどのように比較されるかを知りたいと思います.ビデオゲームやロボット制御などの他のアプリケーションとは対照的に、任意のコンピューターシステムに固有の大きなアクションスペースが強化学習の特定の課題であることがわかりました。資格情報を保存および取得できるエージェントのトレーニングは、エージェントが通常内部メモリを備えていない強化学習手法を適用するときに直面する別の課題です。これらは、ベンチマーク目的でシミュレーションを使用できる他の研究分野です。
本日リリースするコードは、オンラインのKaggleまたはAICrowdのような競争に変換することもでき、大きなアクション スペースを持つパラメーター化可能な環境で最新の強化アルゴリズムのパフォーマンスをベンチマークするために使用できます。その他の関心分野には、自律的なサイバーセキュリティ システムの責任ある倫理的な使用が含まれます。防御エージェントに本質的な利点を与えるエンタープライズ ネットワークをどのように設計すればよいでしょうか?自律的なサイバー攻撃から企業を守りながら、そのようなテクノロジーの悪用を防ぐことを目的とした安全な研究をどのように実施するのでしょうか?
CyberBattleSim は、強化学習をセキュリティに適用する大きな可能性があると信じていることのほんの一部にすぎません。私たちは、研究者やデータ サイエンティストに私たちの実験を構築するよう呼びかけています。この取り組みが拡大し、セキュリティ問題に取り組むための新しく革新的な方法を刺激することを楽しみにしています。
ウィリアム・ブルーム
Microsoft 365 Defender 研究チーム
参考: https ://www.microsoft.com/en-us/security/blog/2021/04/08/gamifying-machine-learning-for-stronger-security-and-ai-models/
Comments