このブログ シリーズのパート 1 で、Steve Miller は、PDB パスとは何か、それらがマルウェアでどのように表示されるか、それらを使用して悪意のあるファイルを検出する方法、およびグループとアクターを関連付けるためにそれらを使用する方法について概説しました。
スティーブが PDB パスの研究を続けるにつれて、より一般的な統計分析の適用に関心を持つようになりました。アーティファクトとしての PDB パスは、いくつかの理由で興味深いユース ケースをもたらします。
まず、PDB アーティファクトはバイナリの機能に直接結び付けられていません。コンパイル プロセスの副産物として、開発環境に関する情報が含まれており、プロキシによってマルウェアの作成者自身も含まれています。ファイルの機能ではなく、キーボードの後ろにいる人間とこれほど興味深い結びつきを持つ静的なマルウェア機能に遭遇することはめったにありません。
第 2 に、ファイル パスは非常に複雑なアーティファクトであり、さまざまなエンコーディングが可能です。私たちは個人的に、より便利な方法でパスを解析およびエンコードする方法を理解するために、より多くの時間を費やす言い訳を見つけたくてたまらなかった.これは、この分野に飛び込み、さまざまなモデルでファイル パスを表現するためのさまざまなアプローチをテストする機会を提供しました。
私たちのプロジェクトの目的は次のとおりです。
- PDB パスの大規模なデータ セットを構築し、いくつかの統計手法を適用して、潜在的に新しい署名用語とロジックを見つけます。
- この問題に機械学習分類アプローチを適用することで、手作りの署名を書くよりも検出が改善されるかどうかを調査します。
- バイナリ分析用の弱いシグナルとして PDB 分類器を構築します。
まず、データの収集を開始しました。内部および外部のソースから取得したデータセットは、200,000 を超えるサンプルから始まりました。 PDB パスで重複排除すると、約 50,000 のサンプルが得られました。次に、これらのサンプルを一貫してラベル付けする必要があったため、さまざまなラベル付けスキームを検討しました。
PDB パスによるバイナリのラベル付け
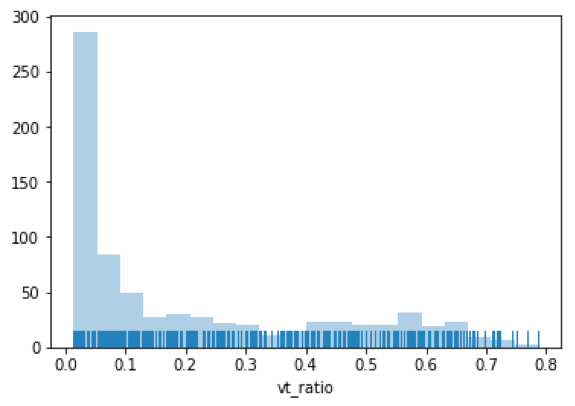
バイナリの多くについては内部 FireEye ラベルがあり、その他については VirusTotal (VT) でハッシュを調べて検出率を調べました。これでサンプルの大部分がカバーされました。比較的小さなサブセットについては、内部エンジンと VT の結果の間に不一致がありました。これは、もう少し微妙なポリシーに値するものでした。意見の不一致は、ほとんどの場合、当社の内部評価でファイルが無害であると判断されたというものでしたが、VT の結果は、ファイルを悪意のあるものとして検出したベンダーの割合がゼロではないことを示しました。これらのケースでは、「VT 比率」、つまりファイルに悪意のあるラベルを付けたベンダーの割合をプロットしました (図 1)。

これらのサンプルの大部分は、VT 検出率が 0.3 未満であり、そのような場合、バイナリを良性と分類しました。残りのサンプルでは、すべて悪意のあるものとしてマークするか、トレーニング セットから完全に削除するかの 2 つの方法を試しました。これら 2 つのポリシー間で分類のパフォーマンスはあまり変化しなかったため、最終的にラベル ノイズを減らすために残りのサンプルを破棄しました。
建物の特徴
次に、機能の構築を開始する必要がありました。ここから楽しみが始まりました。何十もの PDB パスを見て、アナリストに「飛び出す」さまざまなことを記録し始めました。前述のように、ファイル パスには、単なる文字列ベースの成果物というだけでなく、大量の暗黙的な情報が含まれています。ファイル パスは、ファイル システム上の場所を表すという点で地理的な場所に似ている、または一連の従属アイテムを反映するという点で文に似ているというのが、私たちが役立つとわかった例えです。
この点をさらに説明するために、次のような単純なファイル パスを考えてみましょう。
C:UsersWorldDesktopduckZbw138ht2aeja2.pdb ( ソース ファイル)
このパスから、次のことがわかります。
- このソフトウェアは、コンピューターのシステム ドライブでコンパイルされました。
- ユーザー プロファイルのユーザー ‘World’ の下
- プロジェクトは、デスクトップの「duck」というフォルダで管理されます
- ファイル名は高度なエントロピーを持ち、覚えにくい
対照的に、次のようなものを検討してください。
D:VSCORE5BUILDVSCorereleaseEntVUtil.pdb ( ソース ファイル)
これは次のことを示します。
- 外部ドライブまたはセカンダリ ドライブでのコンパイル
- 非ユーザー ディレクトリ内
- 「ビルド」や「リリース」などの開発用語が含まれています
- 賢明で半記憶に残るファイル名を使用する
これらの違いは比較的単純で、一方がマルウェア開発を代表し、もう一方がより「正当に見える」開発環境を代表する理由について直感的に理解できます。
機能表現
これらの違いをモデルにどのように表現すればよいでしょうか?最も簡単で明白なオプションは、各パスの統計を計算することです。フォルダーの深さ、パスの長さ、エントロピー、数字、文字、PDB ファイル名の特殊文字などのカウントなどの機能は、簡単に計算できます。
ただし、データセットに対する評価では、これらの機能はクラスをうまく分離するのに役立ちませんでした。以下は、悪意のあるサンプルと無害なサンプルのクラス間でのこれらの機能の分布の詳細を示すいくつかの図です。
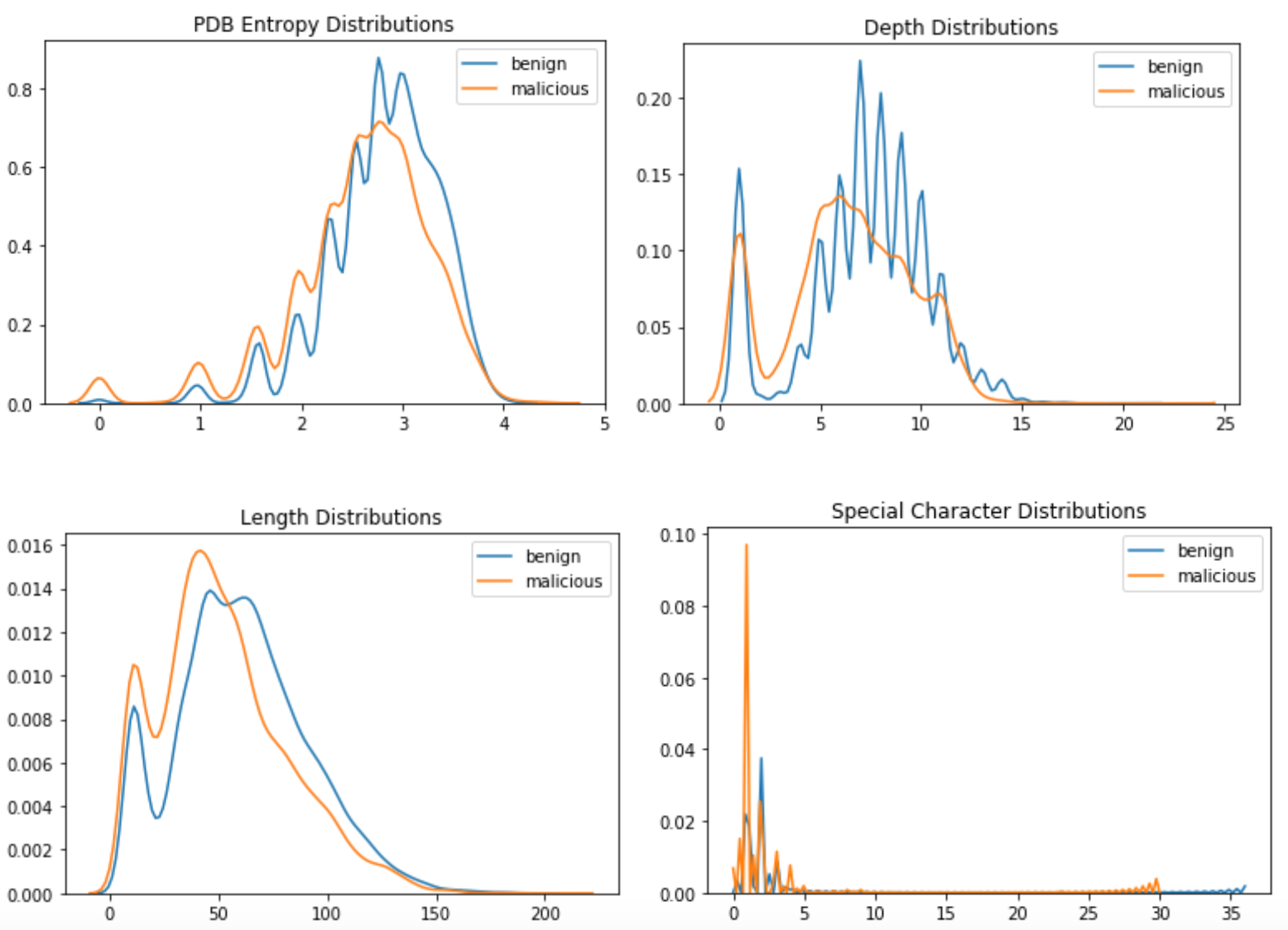
無害なディストリビューションと悪意のあるディストリビューションの間にはある程度の分離がある可能性がありますが、これらの機能だけでは効果的な分類器にはつながらない可能性があります (私たちが試しました)。さらに、これらの違いを明示的な検出ルールに簡単に変換することはできませんでした。抽出する必要のあるパスにはさらに多くの情報が含まれていたため、ディレクトリ名自体をエンコードする方法を検討し始めました。
正規化
他のデータセットと同様に、パスを正規化するためにいくつかの手順を実行する必要がありました。たとえば、個々のユーザー名の出現は、インテリジェンスの観点からは興味深いかもしれませんが、実際には同じ意味を持つ場合、別個のエンティティとして表されます。したがって、この表現を正規化するために、ユーザー名を検出して <username> に置き換える必要がありました。バージョン番号やランダムに生成されたディレクトリなどの他のフォルダーの特異性も、同様に <version> または <random> に正規化できます。
したがって、典型的な正規化されたパスは次のようになります。
C:UsersjsmithDocumentsVisual Studio 2013Projectsmkzyu91952mkzyu91952objx86Debugmkzyu91952.pdb
これに:
c:users<ユーザー名>documentsvisual studio 2013projects<ランダム><ランダム>objx86debugmkzyu91952.pdb
PDB ファイル名自体が正規化されていないことに気付くかもしれません。この場合、ファイル名自体から機能を取得したかったので、そのままにしました。他のアプローチは、それを正規化すること、または同じファイル名文字列「mkzyu91952」がパスの前に現れることに注意することです。ファイル パスを処理する際に使用できる機能は無限にあります。
ディレクトリ分析
ディレクトリを正規化したら、各ディレクトリ用語を「トークン化」して、統計分析を開始できます。この分析の主な目的は、悪意に強く対応するディレクトリ用語があるかどうか、または同様の動作を示すペアやトリプレットなどの単純な組み合わせがあるかどうかを確認することでした。
クラスを簡単に分離できる単一のディレクトリ名は見つかりませんでした。それは簡単すぎるでしょう。ただし、「デスクトップ」などのディレクトリとの一般的な相関関係は、悪意のある可能性がやや高いことや、Z: などの共有ドライブの使用が無害なファイルであることを示していることがわかりました。これは、「正当な」ソフトウェア開発プロセスが必要とする可能性のあるより協調的な環境を考えると、直感的に理にかなっています。もちろん、多くの例外があり、これが問題を難しくしている理由です。
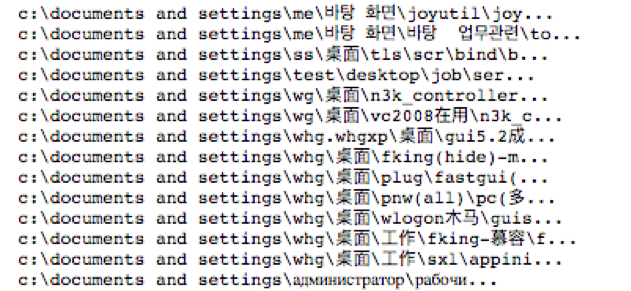
少なくとも私たちのデータセットで見つかったもう 1 つの強力な兆候は、「デスクトップ」という単語が英語以外の言語であり、特に異なるアルファベットである場合、その PDB パスが悪意のあるファイルに結び付けられる可能性が非常に高いことです (図 2)。潜在的に有用ですが、これはデータセットの地理的偏りを示している可能性があり、このタイプの署名が一般化するかどうかを確認するには、さらに調査を行う必要があります.
さまざまなトークン化スキーム
ファイル パスのディレクトリを記録する場合、パスを表す方法はいくつかあります。このパスを使用して、これらのさまざまなアプローチを説明しましょう。
c:LeavesmellLongruleThis.pdb ( ファイル)
言葉の袋
非常に単純な方法の 1 つは、「 bag-of-words 」アプローチです。これは、パスを、パスに含まれる個別のディレクトリ名のセットとして単純に扱います。したがって、前述のパスは次のように表されます。
位置分析
私たちが検討したもう 1 つの方法は、ドライブからの距離として、各ディレクトリ名の位置を記録することでした。これにより、深さに関するより多くの情報が保持され、デスクトップ上の「ビルド」ディレクトリは、9 ディレクトリ下の「ビルド」ディレクトリとは異なる方法で処理されます。この目的のために、ドライブは常に同じ深さになるため、ドライブを除外しました。
[‘leave_1′,’smell_2′,’long_3′,’rulethis_4’]
N グラム分析
最後に、パスを n グラムに分割する方法を調べました。つまり、隣接する n 個のディレクトリの別個のセットとして。たとえば、このパスの 2 グラム表現は次のようになります。
これらの各アプローチをテストしたところ、位置分析と n-gram にはより多くの情報が含まれていましたが、最終的には bag-of-words が最も一般化されているように見えました。さらに、bag-of-words アプローチを使用すると、後のセクションで示すように、結果のモデルから簡単な署名ロジックを抽出することが容易になりました。
用語共起
パスごとに bag-of-words ベクトルを作成したため、無害なファイルと悪意のあるファイル間で用語の共起を評価することもできました。用語のペアの共起を評価したところ、実際に開発環境の 2 つの非常に異なる図を描く興味深いペアリングがいくつか見つかりました (図 3)。
|
悪意のあるファイルとの関連付け |
無害なファイルとの関連付け |
|
ユーザー、デスクトップ |
ソース、小売 |
|
ドキュメント、ビジュアル スタジオ 2012 |
オブジェクト、x64 |
|
ローカルの一時的なプロジェクト |
ソース、x86 |
|
ユーザー、プロジェクト |
ソース、win32 |
|
ユーザー、ドキュメント |
小売、動的 |
|
appdata、一時プロジェクト |
ソース、amd64 |
|
ユーザー、x86 |
ソース、x64 |
図 3: 悪意のあるファイルと無害なファイルの相関ペア
キーワード リスト
次に、PDB パスの bag-of-words 表現により、約 70,000 の異なる用語の明確なセットが得られました。これらの用語の大部分は、データセット全体で 1 回または 2 回発生し、「ロングテール」分布として知られる結果になりました。図 4 は、最も一般的な上位 100 の用語のみを降順に並べたグラフです。
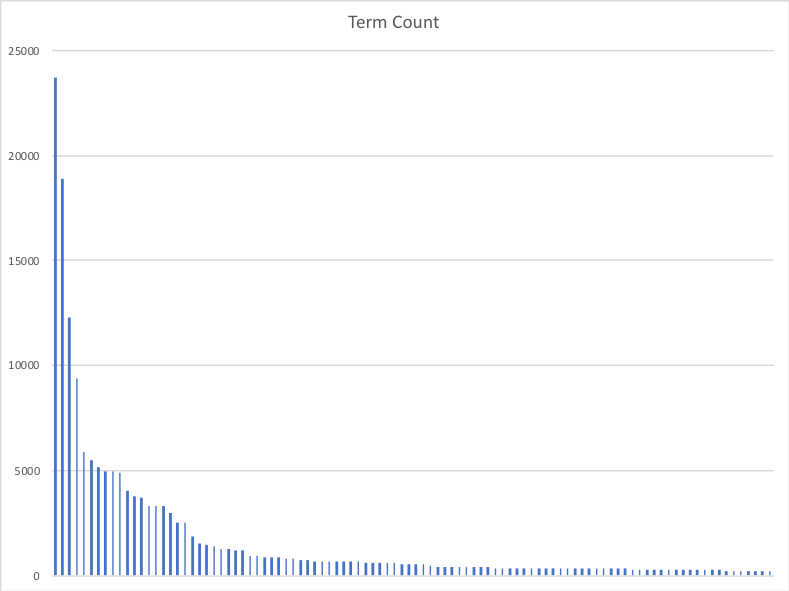
ご覧のとおり、カウントは急速に減少し、ほんの数回しか現れない膨大な量の用語を処理することになります。大量の情報を失うことなくこの問題を解決する非常に簡単な方法の 1 つは、特定の数のエントリの後にキーワード リストを単純に切り取ることです。たとえば、上位 50 個のフォルダー名 (正常なファイルと不適切なファイルの両方) を取得し、それらをキーワード リストとして保存します。次に、このリストをデータセット内のすべてのパスと照合します。機能を作成するには、各一致をワンホット エンコードします。
任意にカットオフを設定するのではなく、モデルの特徴の数を大幅に増やすことなく十分なサンプルをカバーできるように、分布についてもう少し知り、制限を設定するのに適した場所を理解したいと考えました。したがって、最も一般的なものから最も一般的でないものへとリストを繰り返しながら、各用語でカバーされるサンプルの累積数を計算しました。図 5 は、結果を示すグラフです。
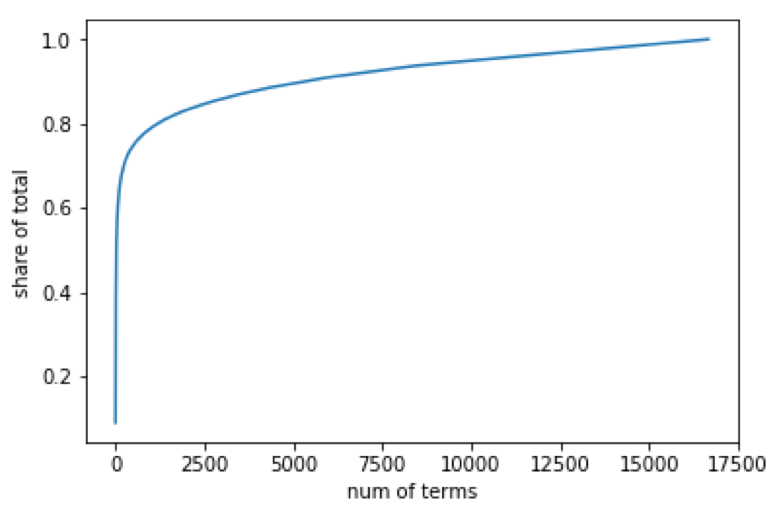
ご覧のとおり、用語のほんの一部で、PDB パスの累積合計のかなりの割合に到達できます。データセットの約 70% に単純なカットオフを設定すると、総語彙は約 230 語になりました。これにより、あまりにも多くの機能 (したがってディメンション) でモデルを爆破することなく、データセットに関する十分な情報が得られました。これらの用語の存在をワンホット エンコーディングすることは、パスに存在するディレクトリ名を特徴付ける最後のステップでした。
YARA署名は木に生えます
いくつかの統計機能とワンホット エンコードされたキーワード マッチを備えて、現在特徴付けられているデータセットでいくつかのモデルのトレーニングを開始しました。そうすることで、モデルのトレーニングと評価のプロセスを使用して、より良い署名を構築する方法についての洞察を得たいと考えました。効果的な分類モデルを開発した場合、それは追加の利点になります。
ツリーベースのモデルは、2 つの理由からこのユース ケースに適していると感じました。第一に、ツリーベースのモデルは、ある程度の解釈可能性を必要とし、量的特徴とカテゴリ特徴のブレンドを使用するドメインで、これまでうまく機能してきました。次に、使用した機能の大部分は、YARA 署名で表現できるものです。したがって、私たちのモデルが多数の PDB ファイルを分離するブール論理分岐を構築した場合、これらを署名に変換できる可能性があります。これは、強力な分類器を構築するために他のモデル ファミリーを使用できないと言っているわけではありません。ロジスティック回帰から深層学習に至るまで、他の多くのオプションを検討できます。
最大深度や葉ごとの最小サンプルなど、いくつかの「ハイパーパラメータ」を設定して、特徴付けられたトレーニング セットをディシジョン ツリーに入力しました。また、これらのハイパーパラメータのスライディング スケールを使用してツリーを動的に作成し、本質的に、何が揺れたのか見てください。図 6 のようなトレーニング済みのデシジョン ツリーを調べることで、すぐに新しいシグネチャを作成することができました。
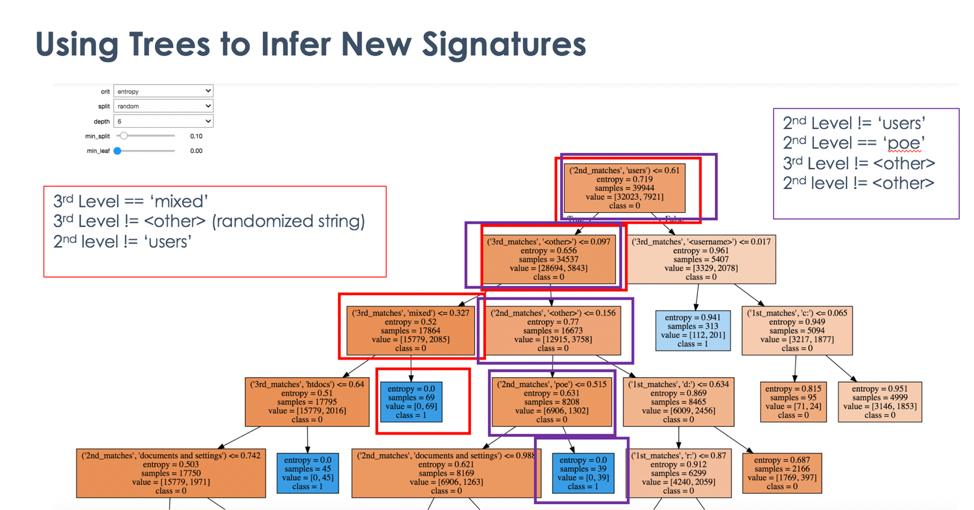
意思決定ツリー内で、他にもいくつかの興味深いヒントが見つかりました。完全に、またはほぼ完全に悪意のあるサブグループになった用語には、次のものがあります。
|
ディレクトリターム |
ハッシュの例 |
|
ポー |
a6b2aa2b489fb481c3cd9eab2f4f4f5c 92904dc99938352525492cd5133b9917 444be936b44cc6bd0cd5d0c88268fa77 |
|
xampp |
4d093061c172b32bf8bef03ac44515ae 4e6c2d60873f644ef5e06a17d85ec777 52d2a08223d0b5cc300f067219021c90 |
|
一時プロジェクト |
a785bd1eb2a8495a93a2f348c9a8ca67 c43c79812d49ca0f3b4da5aca3745090 e540076f48d7069bacb6d607f2d389d9 |
|
スタブ |
5ea538dfc64e28ad8c4063573a46800c adf27ce5e67d770321daf90be6f4d895 c6e23da146a6fa2956c3dd7a9314fc97 |
また、「WindowsApplication1」という用語が非常に役立つこともわかりました。このディレクトリを含むデータセット内のファイルの 89% は悪意のあるものでした。大雑把な調査によると、これは Visual Studio を使用して Windows バイナリをコンパイルするときに生成される既定のディレクトリです。繰り返しになりますが、これはマルウェア作成者を見つけるのに直感的な意味を持ちます。さまざまなパラメーターを使用した決定木のトレーニングと評価は、潜在的な新しい署名用語とロジックを発見する上で非常に生産的な作業であることが判明しました。
分類精度と所見
PDB のパスと特徴の大規模なデータセットができたので、従来の分類子をトレーニングして、良いファイルと悪いファイルを区別できるかどうかを確認したいと考えました。いくつかの調整を加えたランダム フォレストを使用すると、10 回の相互検証で平均 87% の精度を達成することができました。ただし、再現率 (モデルで特定できた悪いものの割合) は 89% と比較的高かったものの、マルウェアの精度 (悪いと見なされたものの実際には悪いものの割合) は非常に低く、 50%未満。これは、このモデルを単独の検出プラットフォームとして実際に展開した場合、マルウェア検出にこのモデルを単独で使用すると、許容できないほど多くの誤検出が発生することを示しています。ただし、他のツールと組み合わせて使用 すると、これは分析を支援する有用な弱い信号になる可能性があります.
結論と次のステップ
統計的な PDB 分析の旅では、魔法のマルウェア分類子は得られませんでしたが、期待していた多くの有用な発見が得られました。
- 開発中の他のモデルに移植可能ないくつかのファイルパス機能機能を開発しました。
- データセットの統計分析を掘り下げることで、YARA 署名に含める新しいキーワードとロジック ブランチを特定することができました。これらのシグネチャはその後展開され、新しいマルウェア サンプルが発見されました。
- 私たちは、PDB パスに関する多くの一般的な研究上の質問に答え、データで十分にテストしていなかったいくつかの理論を払拭することができました。
独立した分類器を構築することが主な目標ではありませんでしたが、最終的なモデルの精度を向上させるために改善を行うことができます。さらに大規模で多様なデータセットを生成することは、精度、再現率、および精度に最大の影響を与える可能性があります。さらなるハイパーパラメータ調整と機能エンジニアリングも役立つ可能性があります。 LSTMなどのさまざまな深層学習手法を使用したテキスト分類に関する確立された研究が多数あり、より大きなデータセットに効果的に適用できます。
PDB パスは、サイバー セキュリティの分野で遭遇するファイル パスの小さなファミリの 1 つにすぎません。初期の感染、ステージング、または攻撃ライフサイクルの別の部分のいずれであっても、フォレンジック分析中に見つかったファイル パスから、敵対者の活動に関する非常に有用な情報が明らかになる可能性があります。その情報を適切に抽出して表現する方法について、コミュニティによるさらなる研究を期待しています。


Comments