情報操作がソーシャル メディアで盛んになった理由の 1 つは、安価に実施でき、リスクが比較的低く、すぐにグローバルにリーチでき、プラットフォームによってインセンティブが与えられる種類のバイラル増幅を利用できることです。調整されたアカウントのネットワークを使用して、ソーシャル メディア主導の情報操作は、特定の政治的物語を促進したり、世論を操作したり、不和を助長したり、戦略的なイデオロギー的または地政学的な目的を達成するために設計されたコンテンツを広めたり増幅したりします。 FireEye の最近の公開レポートは、この活動の手段としてのソーシャル メディアの使用が絶えず進化していることを示しており、本物でないニュース サイトやソーシャル メディア アカウントのネットワークを利用したものや、実在の個人になりすまして正当な情報を利用したものなど、イランの政治的利益を支援する情報操作を強調しています。 報道機関。
この種の高度なアクティビティを特定するには、多くの場合、人間のアナリストの専門知識が必要です。結局のところ、そのようなコンテンツは本物のオンライン アクティビティを模倣するために意図的かつ説得力を持って作成されているため、何気ない観察者が適切に検証することは困難です。このような作戦の背後にいるアクターは、彼らの所属について透明性がなく、多くの場合、精巧な偽のペルソナやその他の作戦上のセキュリティ対策の採用を通じて、彼らの起源を隠蔽するための協調的な努力を行っています.これらの操作は意図的に人間を欺くように設計されているため、自動化に目を向けて、この増大する脅威を理解し、検出できるようにすることはできますか?ソーシャル メディアの異質性、トラフィックの多さ、規模の大きさにもかかわらず、アナリストがこのアクティビティを簡単に発見して調査できるようにすることはできますか?
このブログ投稿では、FireEye データ サイエンス (FDS) チームが FireEye の Information Operations Analysis チームと協力して、ニューラル言語モデルを使用してソーシャル メディアの情報操作をよりよく理解し、検出する方法の例を説明します。
|
ハイライト
|
背景: GPT-2 を転移学習に使用する
OpenAI の最新の Generative Pre-trained Transformer (GPT-2)は、原因言語モデリング タスクで教師なしでトレーニングされたオープン ソースのディープ ニューラル ネットワークです。この言語モデリング タスクの目的は、前のコンテキストから文の次の単語を予測することです。つまり、トレーニングされたモデルが最終的に言語を生成できるようになります。モデルが次の単語を正確に予測できる場合、モデルは次の単語を予測するために使用でき、最終的にモデルが完全に首尾一貫した文と段落を生成するまで、次の単語を予測することができます。図 1 は、GPT-2 を使用して生成した言語モデル (LM) 予測の例を示しています。テキストを生成するために、生成の終了を知らせる <|endoftext|>単語を予測するまで、モデルによって予測された候補単語の分布から 1 つの単語が連続的にサンプリングされます。

この合成的に生成されたテキストの品質と、他の多くの自然言語処理 (NLP) ベンチマーク タスクにおける GPT-2 の最先端の精度は、主に、以前の 1) ニューラル ネットワーク アーキテクチャと 2) アプローチに対するモデルの改善によるものです。テキストを表す。 GPT-2 はアテンション メカニズムを使用して、モデルを関連するテキスト シーケンスに選択的に集中させ、位置的に離れた単語間の関係を識別します。アーキテクチャに関しては、Transformer は注意を払って膨大なデータセットのトレーニングに必要な時間を短縮します。また、長いテキストをモデル化し、他の競合するフィードフォワードおよび再帰型ニューラル ネットワークよりも優れたスケーリングを行う傾向があります。テキストを表現するという点では、単語の埋め込みは、ニューラル ネットワークの最初の層だけを初期化するための一般的な方法でしたが、そのような浅い表現は、新しい NLP タスクごとにゼロからトレーニングする必要があり、新しい語彙に対処する必要がありました。代わりに、GPT-2 は階層表現を使用してすべてのモデルのレイヤーを事前トレーニングします。これにより、言語のセマンティクスがより適切にキャプチャされ、他の NLP タスクや新しい語彙に容易に移行できます。
この転移学習法は、新しい NLP タスクごとにゼロから始めることを避けることができるため、有利です。転移学習では、大量のデータが利用可能な初期タスク用に事前トレーニングされた大規模な汎用モデルから開始します。次に、モデルが取得した知識を活用して、別の小さなデータセットでさらにトレーニングし、その後の関連するタスクで優れたパフォーマンスを発揮できるようにします。モデルをさらにトレーニングするこのプロセスは微調整と呼ばれ、基礎となるパラメーターを調整してモデルの一部を再学習することを含みます。微調整は、ゼロからのトレーニングと比較して必要なデータが少ないだけでなく、通常、必要な計算時間とリソースも少なくて済みます。
このブログ投稿では、事前にトレーニングされた GPT-2 モデルから転移学習を実行して、ソーシャル メディアでの情報操作をよりよく理解し、検出する方法を紹介します。トランスフォーマーは、 Attention is All You Needを示しましたが、ここでは、Attention is All They Need であることも示します。転移学習により、情報操作アクティビティをより簡単に検出できるようになる可能性がありますが、同様に、関与しようとするアクターの参入障壁が低くなります。この活動は大規模です。
微調整されたニューラル生成を使用した情報操作アクティビティの理解
一般的なタイプのソーシャル メディア主導の情報操作活動のテーマおよび言語特性を研究するために、まず、テキスト生成を実行できる LM を微調整しました。事前トレーニング済みの GPT-2 モデルのデータセットは、800 万以上の評判の良い Web ページから抽出された 40 GB 以上のインターネット テキスト データで構成されていたため、その世代は、元のデータセット内に存在するテキストに対応する比較的形式的な文法、句読点、および構造を示しています (例: 図 1)。短い長さ、形式ばらない文法、不規則な句読点、および @メンション、#ハッシュタグ、絵文字、頭字語、略語などの構文上の癖があるソーシャル メディアの投稿のように見せるために、事前トレーニング済みの GPT-2 モデルを微調整しました。追加のトレーニング データを使用した新しい言語モデリング タスク。
このブログ投稿で紹介した一連の実験では、この追加のトレーニング データは、ロシアの有名なインターネット調査機関 (IRA) の「トロール ファクトリー」が運営する特定されたアカウントの次のオープン ソース データセットから取得されました。
- NBCNewsによると、2014 年から 2017 年の間に投稿された 200,000 件を超えるツイートが、IRA の「悪意のある活動」に関連しています。
- FiveThirtyEight 、2012 年から 2018 年までの IRA 活動に関連する 180 万件を超えるツイート。 Left Troll、Right Troll、または Fearmonger に分類されたアカウントを使用しました。
- Twitter Elections Integrityでは、2016 年の米国大統領選挙前後の IRA による影響力の取り組みの一環として、約 300 万件のツイートが行われました。
- Reddit Suspicious Accountsは、IRA に由来する疑いのある 944 のアカウントからのコメントと投稿で構成されています。
これら 4 つのデータセットを組み合わせた後、微調整された LM の入力として使用するために、それらから英語のソーシャル メディア投稿をサンプリングしました。微調整の実験は、 HuggingFace のトランスフォーマーライブラリの3 億 5500 万パラメーターの事前トレーニング済み GPT-2 モデルを使用して PyTorch で実行され、最大 8 つの GPU に分散されました。
他の事前トレーニング済み LM とは対照的に、 GPT-2 では、新しいダウンストリーム タスクで微調整するために、アーキテクチャの変更とパラメーターの更新を最小限に抑えることができます。上記のデータセットからのソーシャル メディアの投稿を事前トレーニング済みのモデルで処理しただけで、そのアクティベーションは調整可能な重みを介して線形出力レイヤーに供給されました。ここでの微調整の目的は、GPT-2 が最初にトレーニングされたときと同じでした (つまり、次の単語を予測する言語モデリング タスク。図 1 を参照)。ただし、トレーニング データセットにソーシャル メディアの投稿からのテキストが含まれるようになりました。また、各投稿にサフィックスとして<|endoftext|>文字列を追加して、モデルをソーシャル メディア テキストの短い長さに適合させました。つまり、投稿は次のようにモデルにフィードされました。
「#Fukushima2015 ザポロジア原子力発電所はいつでも爆発する可能性があります
そしてそれはひどいです!ああ、神様!とんでもない! #ニュークライン<|文末|>」
図 2 は、IRA データセットで GPT-2 を微調整した後に作成されたいくつかの生成例を示しています。これらのテキスト世代が、ソーシャル メディアをスクロールする際に遭遇する可能性があるものと同じようにフォーマットされていることを観察してください。それらは短くても痛烈であり、政治問題に関する確実性と怒りを表現し、感嘆符のような強調を含んでいます。また、生成されたテキストの最後に位置的に現れるハッシュタグや絵文字などの特異性も含まれており、実際のユーザーが定期的に示すセマンティック スタイルを表しています。

このモデルは、どのようにしてそのような信頼できる世代を生み出すのでしょうか? LM の微調整中に調整された重みに加えて、GPT-2 の Transformer によって学習された基礎となる注意スコアによっても、重労働の一部が行われます。注意スコアは、テキスト シーケンス内のすべての単語間で計算され、次の学習反復で近くの単語がどれほど重要かを判断する際に、1 つの単語がどれほど重要であるかを表します。アテンション スコアを計算するために、Transformer はクエリ ベクトルqとキー ベクトルkの間で内積を実行します。
- qは、現在の隠れた状態をエンコードします。これは、シーケンス内の他の単語を検索して注意を払う単語を表し、その単語のコンテキストを提供するのに役立ちます。
- kは、以前の隠れた状態をエンコードします。これは、クエリ ワードから注意を引く他の単語を表し、現在のコンテキストでそれをより適切に表現するのに役立つ可能性があります。
図 3 は、 bertvizと呼ばれるアテンション視覚化ツールを使用して、 qおよびkの単一ニューロンの活性化に基づいて、この内積がどのように計算されるかを示しています。図 3 の列は、左側の強調表示された単語「America」から右側の単語の完全なシーケンスまでの注意スコアの計算をたどっています。たとえば、「America」という単語に続く「#」を予測することを決定するために、モデルのこの部分では、「ban」、「Immigrants」、「disgrace」などの前の単語に注意を向けます (モデルが「 「Immigrants」は「Imm」と「igrants」に変換されるため、「Immigrants」は、事前トレーニング済みの GPT-2 の元のトレーニング データセット内の構成要素の単語に比べて珍しい単語です)。要素ごとの積は、 qとkの個々の要素がドット積にどのように寄与するかを示します。ドット積は、ネットワークが新しいテキスト シーケンスから学習するときに、各単語と他のすべてのコンテキスト提供単語との関係をエンコードします。内積は、最終的に、ニューラル ネットワークの次の層に供給されるアテンション スコアを出力するソフトマックス関数によって正規化されます。
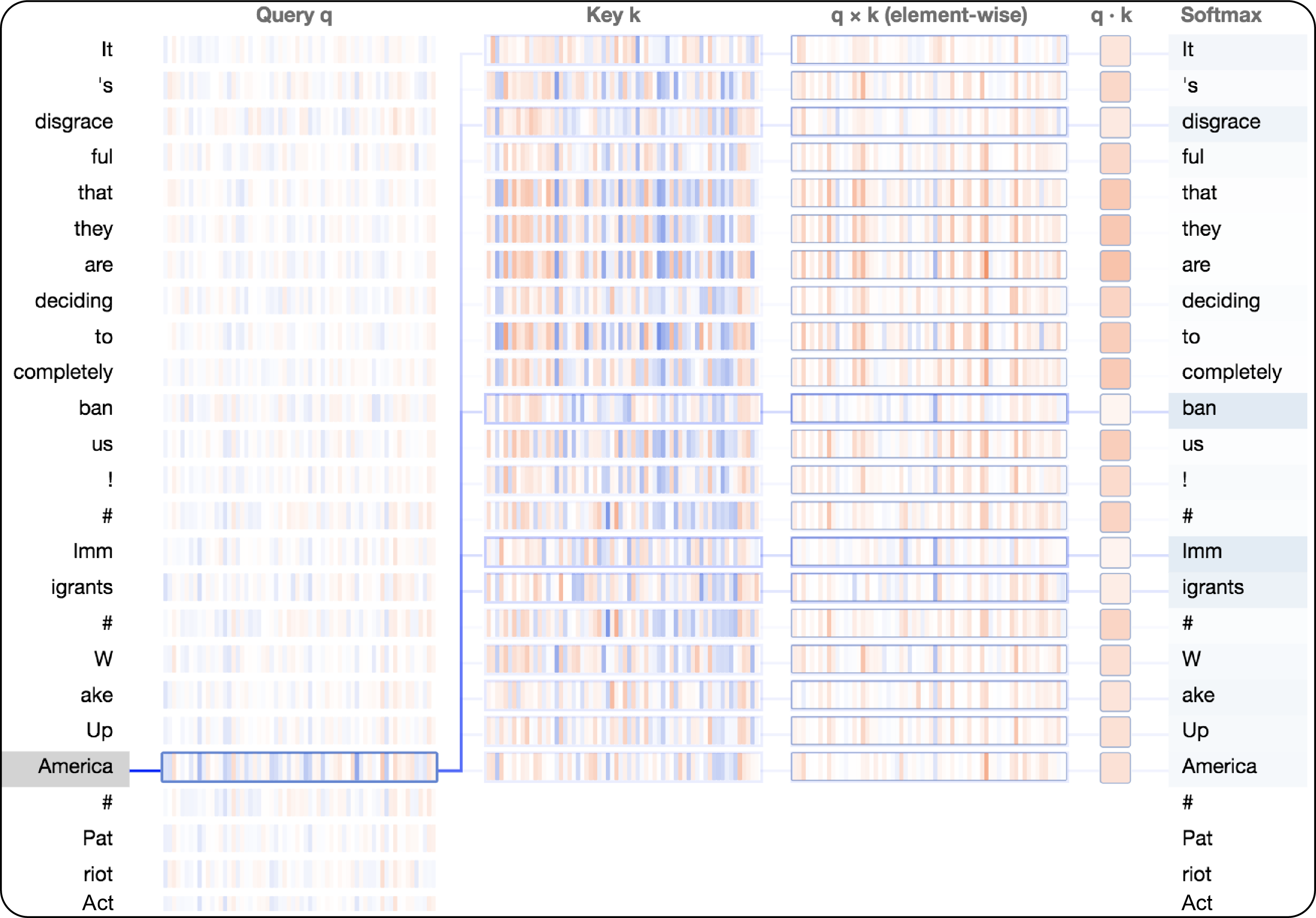
「アメリカ」、「禁止」、「移民」などの単語間の構文上の関係は、情報操作の相互に関連するキーワードやフレーズを特定するのに役立つため、分析の観点から価値があります。これらの指標を使用して、共通の語彙パターンに基づいて疑わしいソーシャル メディア アカウント間を移動したり、共通の物語を特定したり、より積極的な脅威ハンティングを実行したりすることさえできます。上記の例は、この複雑な 3 億 5,500 万のパラメーター モデルの表面をかじったにすぎませんが、トランスフォーマーによって学習された情報を理解するために注意を定性的に視覚化することは、より広範な情報運用活動の一部として展開されている言語パターンへの洞察をアナリストに提供するのに役立ちます。
分類のための GPT-2 の微調整による情報操作アクティビティの検出
ソーシャル メディアでの情報操作活動の発見とトリアージにおける FireEye 脅威アナリストの作業をさらにサポートするために、次に分類を実行する検出モデルを微調整しました。前のセクションで新しい言語モデリング タスクに GPT-2 を適応させたときと同様に、分類タスクのモデルを微調整するために大幅なアーキテクチャの変更やパラメーターの更新を行う必要はありませんでした。ただし、ラベル付けされたデータセットをモデルに提供する必要があったため、ソーシャル メディアの投稿が情報操作に利用されているか (クラス ラベルCLS = 1 )、無害であるか ( CLS = 0 ) に基づいてグループ化しました。
無害な英語の投稿は、検証済みのソーシャル メディア アカウントから収集されました。これらのアカウントは一般に、投稿に多様で無害なコンテンツが含まれている著名人やその他の著名な個人または組織に対応していました。このブログ投稿の目的のために、情報操作関連の投稿は、前述のオープン ソース IRA データセットから取得されました。分類タスクでは、以前に LM の微調整のために結合された IRA データセットを分離し、 CLS = 1に関連付けられたグループのためにそれらの 1 つのみから投稿を選択しました。データセットの選択を定量的に実行するために、各 IRA データセットの LM を微調整して 3 つの異なる LM を生成し、各データセットからの投稿の 33% をテスト データとして保持しました。そうすることで、あるデータセットの LM が他のデータセットから発信された投稿コンテンツをどれだけうまく予測できたかに基づいて、個々の IRA データセット間の重複を定量化することができました。
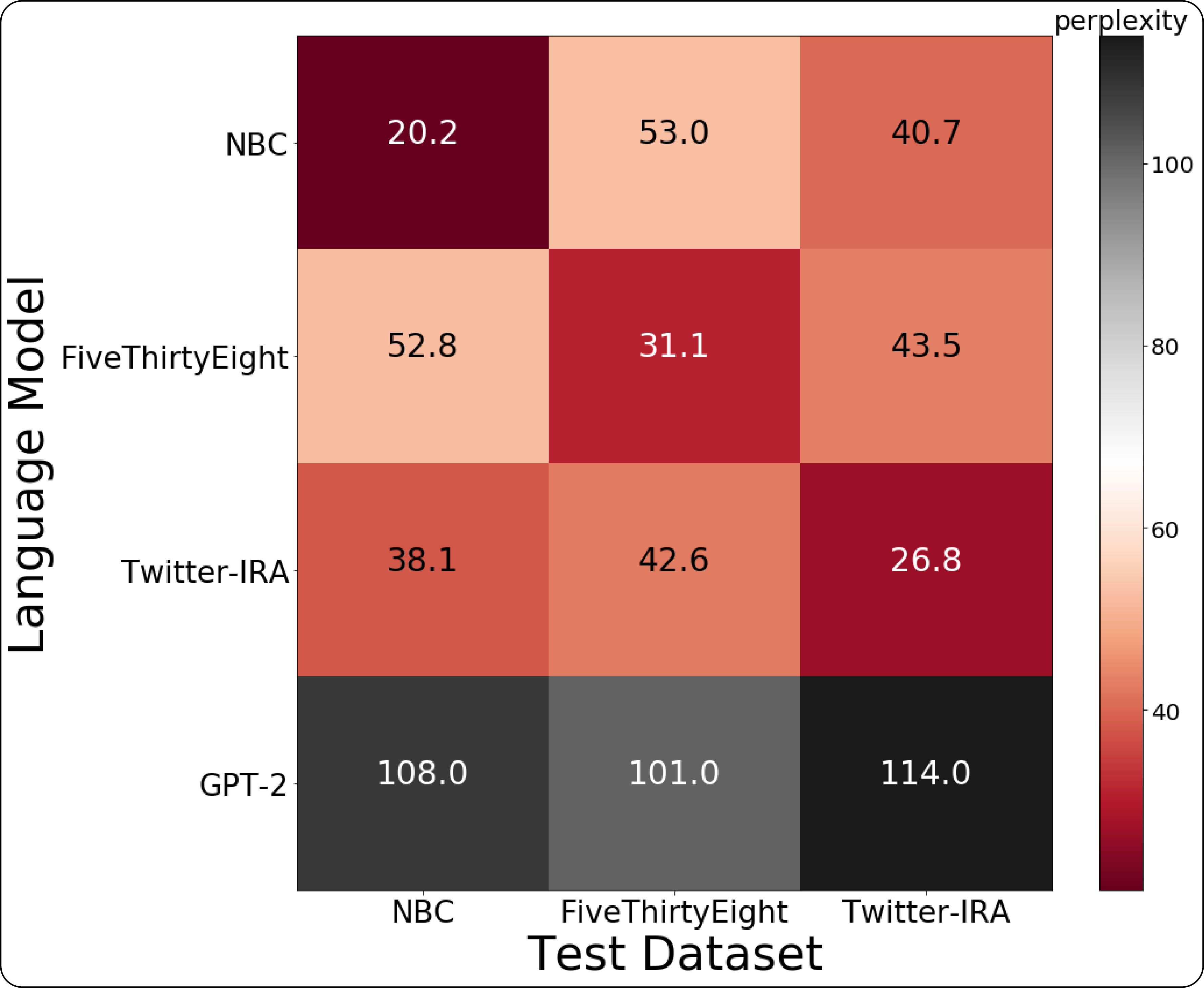
図 4 では、3 つの LM のそれぞれについてパープレキシティ スコアを計算した結果と、各データセットからテスト データを保持した元の事前トレーニング済み GPT-2 モデルを示しています。スコアが低いほど困惑度が高いことを示します。これは、モデルが正しい次の単語を選択する確率を捉えています。最低スコアは、困惑混同行列の主対角線に沿って落ちました。これは、微調整された LM が、独自のデータセット内から発生したテスト データの次の単語を予測するのに最も優れていたことを意味します。 Twitter の Elections Integrity データセットで微調整された LM は、提示されたすべてのテスト データセットで平均すると、最も低いパープレキシティ スコアを示したので、分類の微調整を示すために、このデータセットからサンプリングされた投稿を選択しました。
分類タスクを微調整するために、事前トレーニング済みの GPT-2 モデルを使用して、選択したデータセットの投稿をもう一度処理しました。今回は、アクティベーションは、前のセクションで言語モデリング タスクに使用された単一の出力レイヤーではなく、調整可能な重みを介して2 つの線形出力レイヤーに供給されました。ここで、微調整は、分類損失と補助 LM 損失を伴うマルチタスク目標として定式化されました。これにより、トレーニング中の収束が加速され、モデルの一般化が改善されました。また、投稿の先頭に新しい[BOS] (つまり、Beginning Of Sentence) 文字列を追加し、投稿の末尾に前述の[CLS]クラス ラベル文字列を追加して、各投稿が次のようにモデルに入力されるようにしました。
「[BOS] ケビン・マンディアは @CNBC の @MadMoneyOnCNBC に出演し、@jimcramer と一緒に標的を絞った偽情報について話し合っていました… https://t.co/l2xKQJsuwk[CLS]」
[BOS]文字列は、以前に LM の微調整で使用された<|endoftext|>文字列と同様の区切りの役割を果たし、 [CLS]文字列は、モデルの分類層。上記のソーシャル メディアへの投稿の例は無害なデータセットからのものであるため、このサンプルのラベルは微調整中にCLS = 0に設定されました。図 5A は、微調整中の分類と補助 LM 損失の変化を示しています。図 5B は、約 66,000 のソーシャル メディア投稿で構成されるテスト セットで微調整された分類器のROC 曲線を示しています。損失が低い値に収束し、ROC 曲線下の領域 (つまり AUC) が高いことは、転移学習により、このモデルが IRA 情報操作活動に関連するソーシャル メディアの投稿と良性の投稿を正確に検出できることを示しています。まとめると、これらのメトリックは、微調整された分類子が新しく取り込まれたソーシャル メディアの投稿にうまく一般化され、アナリストが信号をノイズから分離するために使用できる機能を提供する必要があることを示しています。
結論
このブログ投稿では、以前は情報操作で利用されていたソーシャル メディアの投稿を含むオープン ソース データセットでニューラル LM を微調整する方法を示しました。転移学習により、これらの投稿を高い AUC スコアで分類することができました。FireEye の脅威アナリストは、この検出機能を利用して、同様の緊急オペレーションを発見してトリアージすることができます。さらに、Transformer モデルがアテンション メカニズムを介してさまざまなテキストにスコアを割り当てる方法を示しました。このビジュアライゼーションは、アナリストが投稿の言語フィンガープリントとセマンティック スタイリングに基づいて敵対者のトレードクラフトを分析するために使用できます。
転移学習により、パープレキシティ スコアの低い信頼できる合成テキストを生成することもできました。攻撃者が効果的な情報操作を考案する際に直面する障壁の 1 つは、標的が置かれている文化的風土のニュアンスと文脈を適切に捉えることです。ここでの演習では、事前にトレーニングされた LM を使用して、このコストのかかるステップを回避できることを示唆しています。LM の世代は、ソーシャル メディアの時代精神を体現するように微調整できます。 GPT-2 の作成者とその後の研究者は、この強力な自然言語生成技術によって可能になる潜在的な悪意のあるユースケースについて警告してきました。ここでは、容易に入手できるオープンソース データを使用して、制御されたオフライン設定で防御アプリケーションのために実施されましたが、私たちの研究はこの懸念を補強しています。 .より強力ですぐに利用できる言語生成モデルへの傾向が続く中、図 5 やGrover などの他の有望なアプローチで示されているように、検出に向けた取り組みを強化することが重要です。
この調査は、FireEye IGNITE University Program の 3 か月間のサマー インターンシップ中に実施されたもので、FDS と FireEye Threat Intelligence の Information Operations Analysis チームとの共同作業を表しています。サイバー セキュリティと機械学習が交差する領域で学際的なプロジェクトに取り組むことに興味がある場合は、2020 年夏のインターンシップへの応募を検討してください。


Comments