マルウェアのバイナリには、数千から数百万の実行可能な命令が含まれている可能性があり、エキスパート レベルのリバース エンジニアでさえ、コード機能をつなぎ合わせるために逆アセンブリの分析に何日も費やすことがあります。関数に繰り返し注釈を付けることは、マルウェア アナリストが分析をより管理しやすいチャンクに分割するために使用できる 1 つの戦略です。ただし、注釈は面倒なプロセスになる可能性があり、多くの場合、さまざまなアナリスト間で構文と関数の選択に一貫性がなくなります。 Mandiant Data Science (MDS) チームとFLAREチームは、最近の NVIDIA GPU Technology Conference (GTC) プレゼンテーションに合わせてこのブログ投稿をリリースし、機械学習を通じてこの負担を軽減するためにどのように協力したかを説明しました。
|
ハイライト
|
背景: 逆アセンブルと逆コンパイルによる静的マルウェア分析
基本的な静的および動的分析手法は、最初のマルウェア トリアージ中に予備的な手掛かりを引き出すのに役立ちますが、マルウェア作成者の意図した目的に近づくには、より詳細な分析が必要です。典型的なプログラムは、関連する機能をfunctionsと呼ばれるコード構造にグループ化します。これは、ユーザーによって作成されたか、既存のライブラリから取得されます。マルウェア アナリストとリバース エンジニアは、 NSA の GhidraやHex-Rays の IDA Proなどの逆アセンブラーを使用して機能をざっと調べ、低レベルのアセンブリ言語と高レベルの C に似た疑似コードを生成します。ヒューリスティックを適用して、インポートの使用、特定のアセンブリ命令の存在、データ参照、さらにはグラフ構造などの機能に基づいて関数に注釈を付けます。関数に注釈を付ける作業は反復的なプロセスであり、マルウェアの全体的な機能をより包括的に把握するための重要なステップです。
マルウェア アナリストは、分析中に 1 つの機能を何度も再確認し、そのたびに注釈を更新することがあります。これは、非常に長く退屈なプロセスに積み重なる可能性があります。専門的な分解ツールは、関数を自動的に認識して注釈を付けることができるため、時間が重要な調査中のアナリストの労力を軽減できます。たとえば、IDA はFLIRTやLuminaなどのメカニズムを利用して、以前に識別された関数名にラベルを付け、ユーザー間で、また時間を超えて注釈を共有できるようにします。残念ながら、そのような署名は新しいサンプルに一般化できないことが多く、操作 (たとえば、異なるコンパイル オプション) に対して耐性がありません。また、署名は、コンパイラによって追加されたライブラリ コードのみを説明し、ユーザー定義関数の大規模なセットを注釈なしで残します。
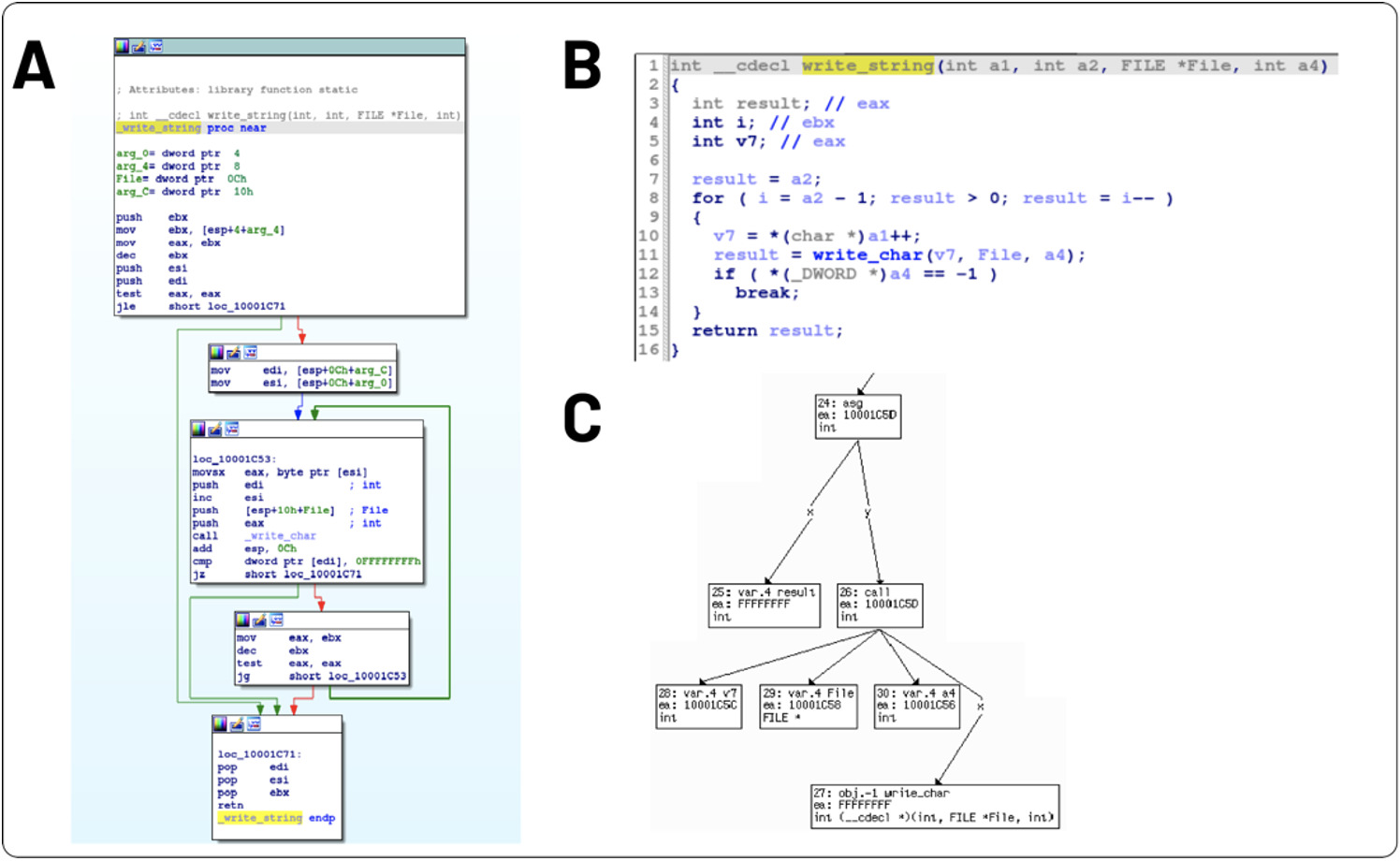
図 1 に表示されている 3 つのビューは、以前にwrite_string注釈が付けられた関数を表しています。図 1A は逆アセンブリコントロール フロー グラフ (CFG)ビューを示しています。このビューでは、一連のアセンブリ命令が有向グラフとして表される基本ブロックにグループ化されています。エッジの矢印は、分岐やループなどのコーディング構造を決定できるコード実行パスを示しています。図 1B では、逆コンパイラが図 1A の関数を、よりコンパクトで理解しやすい高水準言語にレンダリングします。逆コンパイルされた出力が生成されると、最適化が逆アセンブリに適用され、一般に簡略化された疑似コードが提供されます。 抽象構文ツリー (AST)は、図 1C の疑似コードから導き出すことができます。ここで、内部ノードはプログラミング言語構造を表し、リーフ ノードには数値データと文字列データが含まれています。

write_stringという名前のサンプル関数の逆アセンブリと逆コンパイルの解釈リバース エンジニアは通常、図 1 に示すようなビューを使用して、関数の目的を判断するのに役立てます。たとえば、 write_charの周りのループは、一連の文字が出力されていることを意味する場合があります。一連の文字は文字列である可能性があり、アナリストはこの関数をwrite_stringとしてラベル付けするように促されます。一般に、文字列を出力する機能は、アナリストがあまり関心を持っていません。残念ながら、この機能のリバース エンジニアリングに時間を費やしましたが、悪意のある機能に焦点を当てたほうがよかったでしょう。さらに、どの関数に注釈を付けるか、どの命名規則を適用するかなどの決定は、アナリストによって大きく異なる可能性があります。これら一連の課題により、私たちは次のような疑問を抱くようになりました。関数名のカバレッジを改善し、バイナリ逆アセンブリ内のセマンティクスを標準化して、マルウェアのトリアージを加速するにはどうすればよいでしょうか?
ソースコードからの自然言語の生成 (およびその逆)
入力トークンの構造化されたシーケンスとして逆アセンブリを表し、対応するグラウンド トゥルース関数名をターゲット ラベル トークンのシーケンスとして表すことにより、この問題をニューラル機械翻訳 (NMT) タスクとして組み立てることができます。 Seq2seq および大規模言語モデリング アプローチは、以前はソース コードから自然言語を生成するために適用されており、その逆も同様でした。これには、コードの要約、コードのドキュメント化、変数名の予測、さらにはオートコンプリート タスクなどのユース ケースが含まれます ( OpenAI の Codex モデルを参照)。ただし、これらのアプローチは主に、Python や Java などの高水準のプログラミング言語で動作します。これらの言語は、マシン コードよりも簡潔で読みやすく、順序が直線的で、構文が豊富です。
逆アセンブリを NMT モデルの入力に変換するために、マシン コードの構造化表現からシーケンスを生成した以前の研究から着想を得ました。最初のモデルcode2seqはコードを AST 上のパスのセットとして表し、2 番目のモデルNeroはコードを CFG のノードとエッジとして表します。私たちは、 code2seqのトレーニングに使用される Java および C# ファイルや、 Neroのトレーニングに使用される無害な ELF 実行可能ファイルとは異なり、 マルウェア ユニバースの大部分を構成するWindows Portable Executable (PE) ファイルでモデルをトレーニングしました。
逆コンパイル AST の神経表現
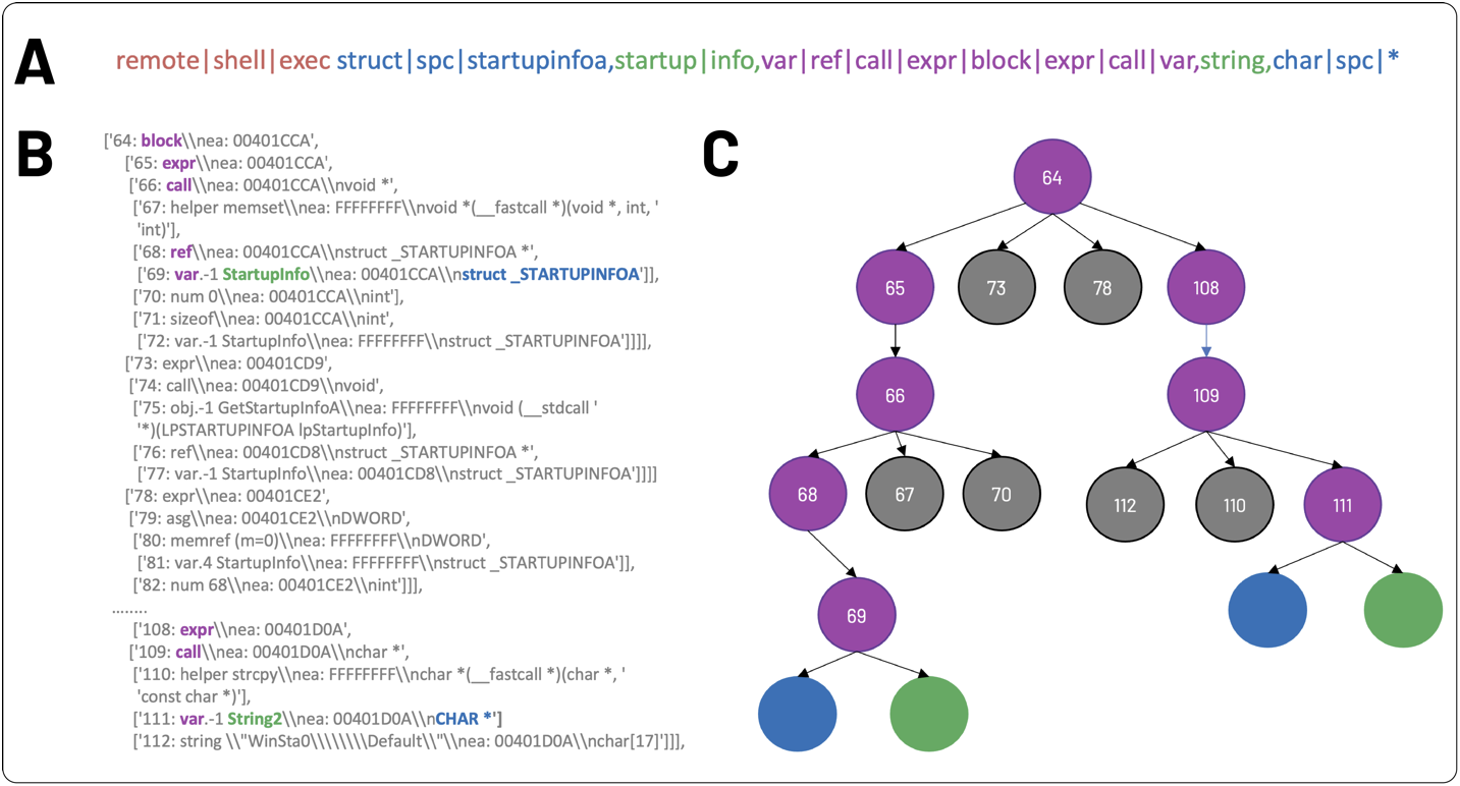
マルウェア関数の逆コンパイルのために、 code2seqアーキテクチャをどのように適応させたのでしょうか? IDA の逆コンパイラからの出力は、AST を介してアナリストに公開されます (図 1C を参照)。 AST リーフはユーザー定義のコード識別子と名前をエンコードし、内部 AST ノードはループ、式、変数宣言などの構造をエンコードします。 code2seqと同様に、Bi-directional Long Short-Term Memory (BiLSTM) ニューラル ネットワーク レイヤーを使用して固定長ベクトルに圧縮されたランダム パスとして AST を表現し、エンコーディング中にこれらのパス埋め込みを AST リーフ トークン埋め込みと連結しました。次に、モデルは、デコード中に関連するASTパスに注意を払い、一連の注釈予測を生成します。 code2seqとは対照的に、リーフ トークンの埋め込みと AST パスの埋め込みに加えて、型と連結型の埋め込みを埋め込みました。
図 2A では、AST 表現の例が、ラベル トークン (赤)、リーフ値トークン (緑)、ノード パス (紫)、および型トークン (青) で構成されています。 AST パス (2A の紫色) は、図 2B の逆コンパイルのスニペット内で強調表示されています。最初のリーフ ノード (つまり、紫色のノード パスのシーケンス) をたどることができます。var69行目)ツリーを上る(つまりref68行目、call66行目、expr65 行目) ルート ノードに到達するまで (つまりblock64 行目)、ツリーを下って戻る前に (すなわちexpr108行目、callこのパスの他のリーフ ノードに到達するまで (つまり、109 行目)var111行目)。図 2C は、2A と 2B からサンプリングされたパスの AST 表現を示しています。関数ごとに最大 200 のこのような AST パスがサンプリングされ、BiLSTM によって順次処理されます。対応するリーフ (緑) トークンとタイプ (青) トークンは、エンコード中に連結される前に個別に埋め込まれます。
逆アセンブリ CFG の神経表現
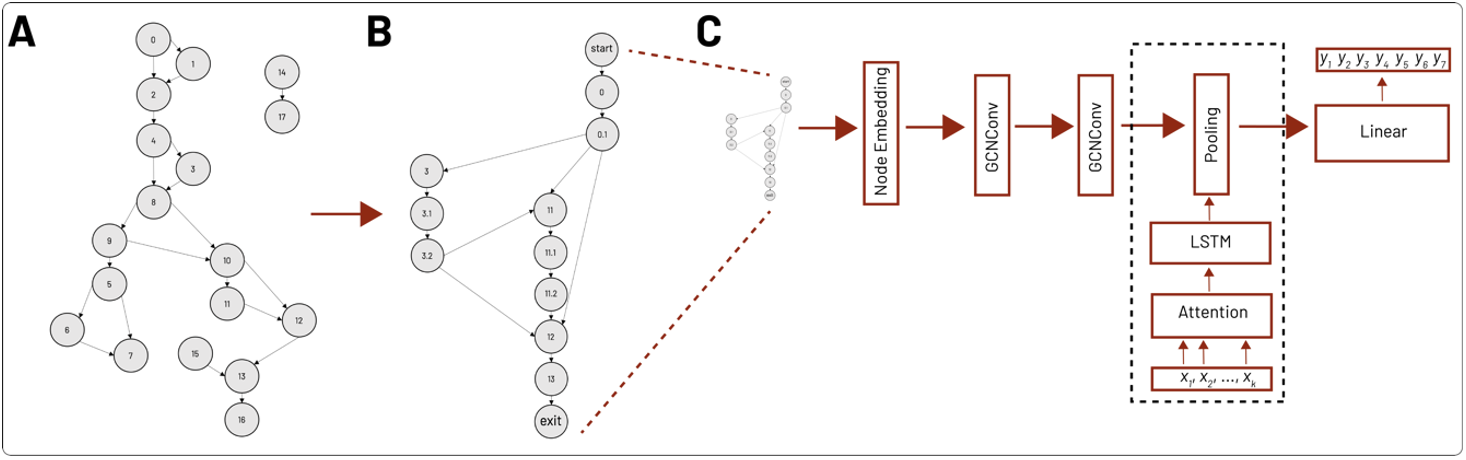
また、IDA からの CFG 出力 (図 1A を参照) を個別の入力表現と見なしました。ここで、ノードは関数の基本的なコード ブロックを表し、エッジはブロック間の分岐やループなどの制御フロー命令を表します。 Neroと同様に、逆アセンブルされた関数から CFG を取得し、各呼び出し命令の呼び出しサイト グラフを再構築し、 Graph Convolutional Network (GCN) を含むいくつかの競合モデルを使用して呼び出しサイトのシーケンスを学習しました。 Neroとは対照的に、追加の引数ソース情報でコール サイト グラフを拡張しませんでした。マルウェアベースの GCN モデルを CFG2Seq と呼びます。
Neroアーキテクチャをマルウェア機能の分解に適応させるために、まず、対応する各 CFG を適切に減らして、選択した呼び出しサイトノードのみを含めました。呼び出しサイト ノードは、CFG の API 呼び出しに関連付けられたノードです。たとえば、図 3A の最初の CFG は、図 3B に示す呼び出しサイト グラフになります。図 3C では、縮小されたグラフは、学習された API 呼び出しの埋め込みで構成される GCN をトレーニングするための入力として使用され、その後に 2 層のグラフ畳み込み (つまり GCNConv) とSet2Set グラフ プーリング層(点線の四角形、 kはノード数) を使用してグラフを要約します。次に、プールされた表現が線形デコーダーに供給され、関数ごとに最大 7 つの出力トークンのシーケンスが予測されました。
方法と結果
入力データセットは、4.3k の悪意のある PE ファイルから抽出された 36 万を超える逆アセンブリ関数と対応する注釈で構成されていました。関数表現と注釈は、内部 AST ノードの深さ優先ハッシュによって重複排除され、その後、 code2seqとNeroの両方で概説されている手順に従って、80% のトレーニング セット、10% の検証セット、および 10% のテスト セットに分割されました。私たちの注釈は、自動生成された IDA 関数名と、Mandiant のリバース エンジニアによって作成された約 10 年分の説明的な関数名を表す格納されたメタデータの独自のデータベースの組み合わせから作成されました。生の注釈文字列は個々の単語にトークン化され、アナリスト間の注釈品質のばらつきを考慮して、トークンを正規化およびマージするように注意が払われました。
ホールドアウト分割の適合率、再現率、および F1 スコアを計算することでモデルを定量的に評価し、PE テスト セットを使用した最高のパフォーマンスのモデルは、型強化されたcode2seqモデル (太字、表 1) であることがわかりました。表 1 の最初の 3 行は、 code2seqおよびNeroの論文で報告されたメトリックを示しています。一方、最後の 3 行は、テスト セットから測定されたメトリックを示しています。異なるデータセットが使用されたため、モデルのパフォーマンスを直接比較することはできません。ただし、私たちのモデルが以前に公開されたものと同様の範囲内でテスト スコアを達成していることを観察できます。これは、悪意のある PE ファイルから逆アセンブルされた低レベルのプログラミング言語にこれらの方法を適用したにもかかわらず、私たちの新しいアプローチの価値を示しています。
|
データセット |
モデル |
精度 |
想起 |
F1 |
|
Javaで |
code2seq |
51.38 |
39.08 |
44.39 |
|
Java-med |
code2seq (型拡張) |
49.15 |
42.35 |
45.50 |
|
GNU エルフ |
ネロ |
48.61 |
42.82 |
45.53 |
|
PEテスト(弊社) |
code2seq |
55.68 |
55.70 |
55.69 |
|
PEテスト(弊社) |
code2seq (型拡張) |
62.12 |
61.10 |
61.60 |
|
PEテスト(弊社) |
CFG2Seq |
55.07 |
43.49 |
48.60 |
次に、2 人のリバース エンジニアに、人気のある本Practical Malware Analysis (PMA)で言及されている、いくつかの逆アセンブルされたマルウェア サンプルから関数に個別に注釈を付けてもらいました。表 2 は、最初の列に型強化されたcode2seqモデルの予測を示し、後続の列にアナリストの注釈を示します。列 A と列 B の注釈パターンの違いに注目してください。 1 人のアナリストが関数にアノテーションを付け、もう 1 人のアナリストがアノテーションを付けない場合もあれば、関数に何をラベル付けするかについて合意していても、まったく異なる命名規則や記述粒度のレベルを使用していた場合もあります。アナリストの選択性と構文の可変性はどちらも、私たちのモデリングが統一されたソリューションを提供する一般的な問題です。
表 2 では、型強化されたcode2seqモデルが、高レベルの API 使用パターン、エンコードやデコードなどのデータ処理パターン、低レベルのライブラリ操作、簡単な API ラッパーなど、さまざまなコード抽象化レベルを説明できることは明らかです。 .多くの場合、モデルは、アナリストがモデルの予測に関する事前知識を持っていないこのより困難な評価設定でも、より多くの有用な関数注釈を正常に予測します。実際には、これらの予測は、リバース エンジニアが特定のマルウェア サンプルをトリアージするときに、推奨されるアノテーション モデルの予測にリアルタイムでアクセスできる、ガイド付きアナリストの設定でさらに役立ちます。
|
モデル予測 |
アナリストA |
アナリストB |
|
[「実行」、「自己」、「削除」、「自己」] |
_delete_myself |
同じ場所 |
|
[‘get’, ‘sedebug’, ‘priv’] |
has_priv |
grant_priv |
|
[‘get’, ‘string’, ‘name’] |
_parsecmd |
|
|
[‘aes’, ‘復号化’] |
|
like_rijndael_routine |
|
[‘tolower’] |
|
tolower_wrapper |
|
[‘get’, ‘reg’, ‘value’, ‘keys’] |
|
vmcheck_reg_devices |
|
[‘inject’, ‘into’, ‘process’] |
|
process_replacement |
|
[‘zb64’, ‘デコード’] |
_base64_decode_おそらく |
b64_decode |
|
[‘作成’, ‘シェル’, ‘スレッド’, ‘シェル’] |
|
レブシェル |
|
[「開始」、「メイン」、「スレッド」] |
|
DllMainThreadStart |
|
[‘dobase64’] |
_base64_encode |
b64encode3 |
|
[「取得」、「http」、「投稿」] |
|
readFromUrl |
|
[‘xor’, ‘データ’] |
_xor_cipher |
デコード |
|
[‘do’, ‘toupper’, ‘ctype’, ‘std’] |
_all_toupper |
ユースケース |
|
[‘get’, ‘system’, ‘directorya’] |
_get_system_directory |
|
|
[‘get’, ‘module’, ‘file’, ‘name’] |
_get_module_file_name |
getModuleNameWrapper |
|
[‘作成’, ‘ディブ’, ‘ウィンドウ’] |
_generate_bitmap |
キャプチャスクリーンショット |
|
[‘get’, ‘rand’, ‘file’, ‘name’] |
|
boolean_instr_func |
|
[‘load’, ‘resource’, ‘by’, ‘name’] |
|
チェックマック |
|
[‘get’, ‘random’, ‘type’] |
_vmchk |
vmcheck_in_vx |
|
[‘rl’, ‘stream’, ‘load’, ‘from’, ‘file’] |
_encrypt_aes_maybe |
暗号ルーチン |
最後に、IDA Pro の既製の署名では認識されなかった実際の例で、モデルの適用可能性を示しました。関数の複雑さは、図 4A から明らかです。FIDL の AST 視覚化この関数の、図 4B の対応する IDA ブロック図表現、および図 4C の対応する CFG は、ネットワークX.この関数は、ほとんどの分析には関係がなく、分析者は、無害で面白くない性質のため、リバース エンジニアリングに時間を費やしたくありません。型強化されたcode2seqモデルは、次の注釈を予測します。グラウンド トゥルース名が _outputなので[‘str’, ‘conv’, ‘format’, ‘uint’]、その複雑さにもかかわらず、この関数がデータ型のありふれたフォーマット変換を担っているという強力な手がかりを提供します.この複雑な関数のレジスタ値とメモリ割り当てを追跡する代わりに、アナリストは時間を節約し、モデルからの予測を調べた後、次の関数に進むことができます。
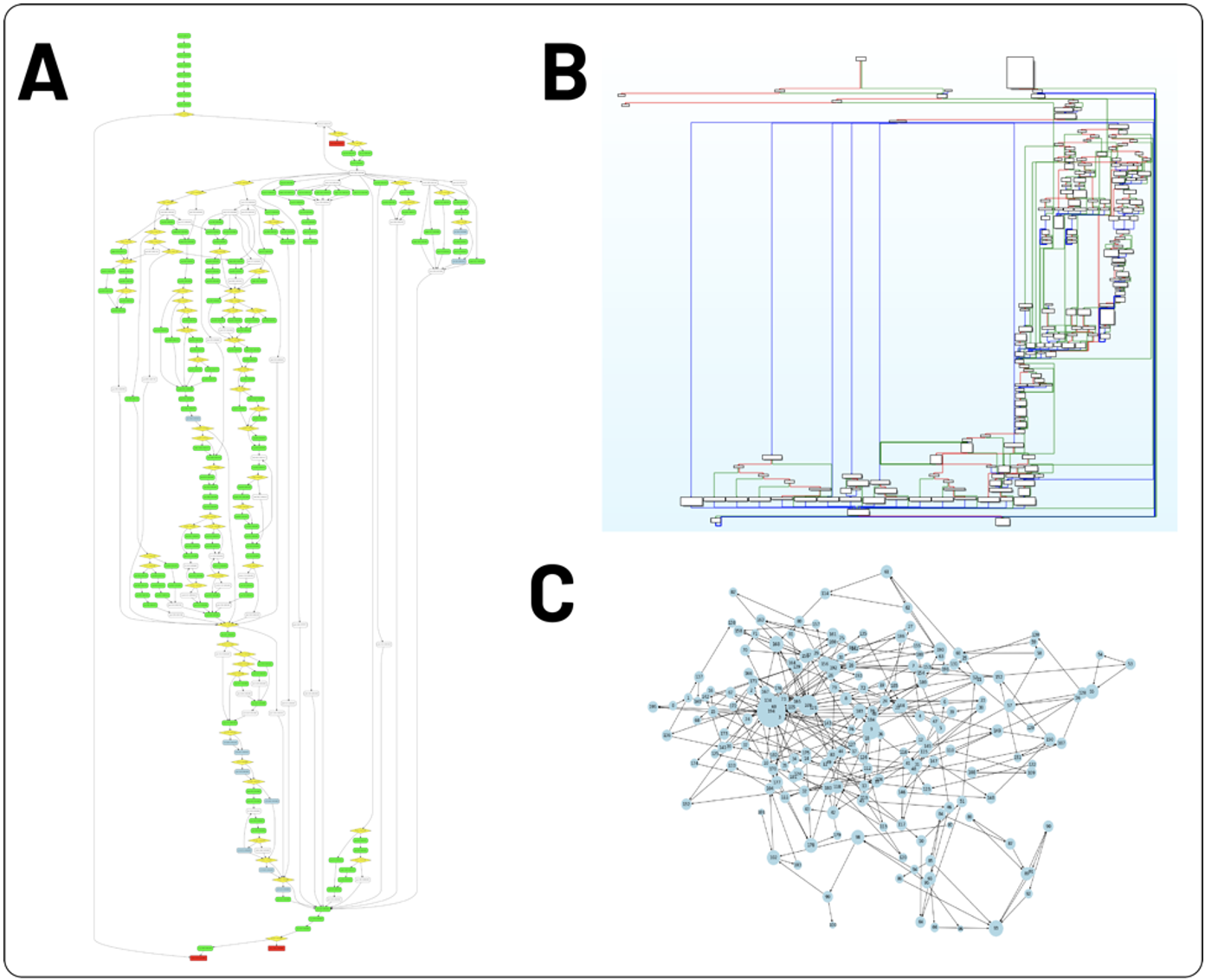
_outputという名前の printf() ファミリで使用されるスキップ可能なユーティリティ関数に正確に注釈を付けることで、不要な時間の浪費を回避するのに役立ちます結論
このブログ投稿では、PE マルウェアの分解から関数名に注釈を付ける方法を学習する、いくつかの異なる機械学習モデルを紹介しました。提案された NMT モデルは、スタンドアロンの逆アセンブラー プラグインとして、または Mandiant のスケーラブルなマルウェア分析パイプライン内の条件付きコンポーネントとして役立ちます。この作業は、MDS と FLARE のチーム間のコラボレーションを表しており、 Mandiant Advantage Platform の一部として悪を発見し、専門知識を自動化し、インテリジェンスを提供するのに役立つ予測モデルを共同で構築しています。このミッションに興味がある場合は、当社の求人への応募を検討してください。
参照: https://www.mandiant.com/resources/blog/annotating-malware-disassembly-functions


Comments